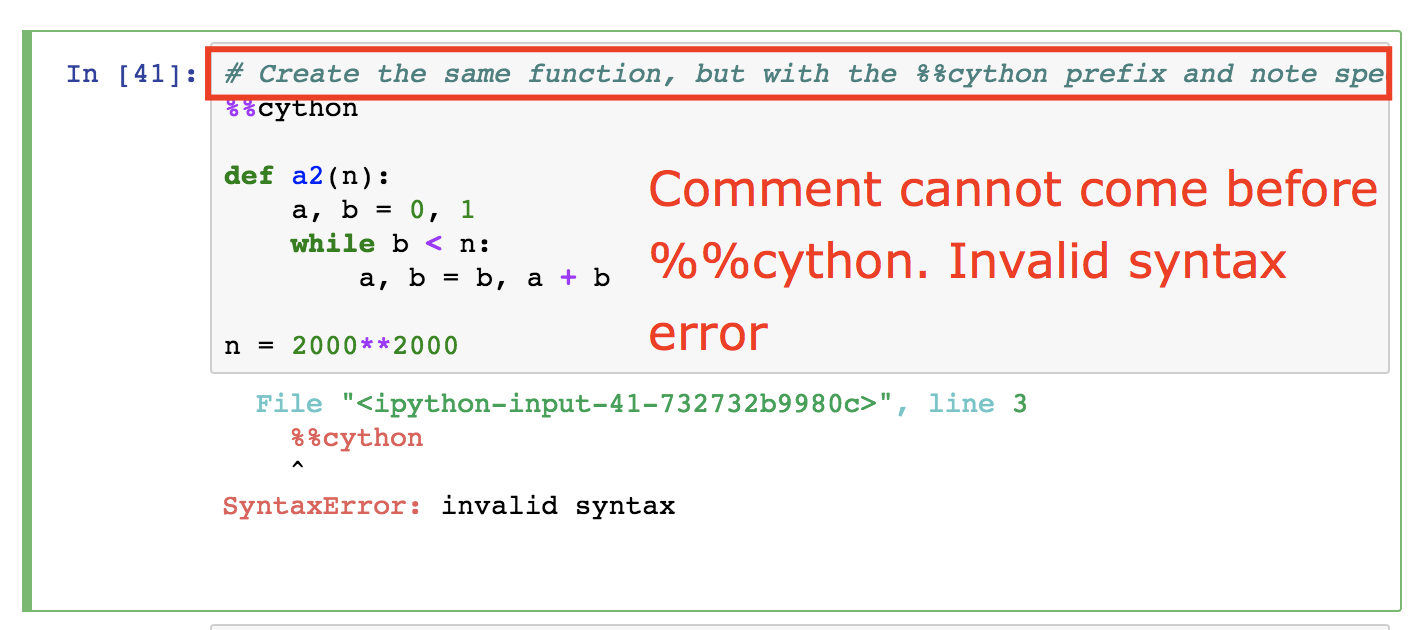
I am getting memory error when executing proc_df on New York City Taxi Fare Prediction training data, which is about 55M rows, 7 columns. Is there any way to make it work at the machine i am using at paperspace (spec below)? Or do i need to upgrade to machine with more memory?
Paperspace machine setup:
MACHINE TYPE: P4000 HOURLY
REGION: CA1
RAM: 30 GB
CPUS: 8
HD: 34.7 GB / 250 GB
GPU: 8 GB
code:
df, y, nas = proc_df(df_raw, 'fare_amount')
error details:
MemoryError Traceback (most recent call last)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/indexing.py in _getbool_axis(self, key, axis)
1495 try:
-> 1496 return self.obj._take(inds, axis=axis)
1497 except Exception as detail:
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/generic.py in _take(self, indices, axis, is_copy)
2784 def _take(self, indices, axis=0, is_copy=True):
-> 2785 self._consolidate_inplace()
2786
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/generic.py in _consolidate_inplace(self)
4438
-> 4439 self._protect_consolidate(f)
4440
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/generic.py in _protect_consolidate(self, f)
4427 blocks_before = len(self._data.blocks)
-> 4428 result = f()
4429 if len(self._data.blocks) != blocks_before:
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/generic.py in f()
4436 def f():
-> 4437 self._data = self._data.consolidate()
4438
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/internals.py in consolidate(self)
4097 bm._is_consolidated = False
-> 4098 bm._consolidate_inplace()
4099 return bm
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/internals.py in _consolidate_inplace(self)
4102 if not self.is_consolidated():
-> 4103 self.blocks = tuple(_consolidate(self.blocks))
4104 self._is_consolidated = True
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/internals.py in _consolidate(blocks)
5068 merged_blocks = _merge_blocks(list(group_blocks), dtype=dtype,
-> 5069 _can_consolidate=_can_consolidate)
5070 new_blocks = _extend_blocks(merged_blocks, new_blocks)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/internals.py in _merge_blocks(blocks, dtype, _can_consolidate)
5091 argsort = np.argsort(new_mgr_locs)
-> 5092 new_values = new_values[argsort]
5093 new_mgr_locs = new_mgr_locs[argsort]
MemoryError:
During handling of the above exception, another exception occurred:
KeyError Traceback (most recent call last)
<ipython-input-23-35a73d8cb330> in <module>()
----> 1 df, y, nas = proc_df(df_raw, 'fare_amount')
~/fastai/courses/ml1/fastai/structured.py in proc_df(df, y_fld, skip_flds, ignore_flds, do_scale, na_dict, preproc_fn, max_n_cat, subset, mapper)
445 if do_scale: mapper = scale_vars(df, mapper)
446 for n,c in df.items(): numericalize(df, c, n, max_n_cat)
--> 447 df = pd.get_dummies(df, dummy_na=True)
448 df = pd.concat([ignored_flds, df], axis=1)
449 res = [df, y, na_dict]
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/reshape/reshape.py in get_dummies(data, prefix, prefix_sep, dummy_na, columns, sparse, drop_first, dtype)
840 if columns is None:
841 data_to_encode = data.select_dtypes(
--> 842 include=dtypes_to_encode)
843 else:
844 data_to_encode = data[columns]
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/frame.py in select_dtypes(self, include, exclude)
3089
3090 dtype_indexer = include_these & exclude_these
-> 3091 return self.loc[com._get_info_slice(self, dtype_indexer)]
3092
3093 def _box_item_values(self, key, values):
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/indexing.py in __getitem__(self, key)
1470 except (KeyError, IndexError):
1471 pass
-> 1472 return self._getitem_tuple(key)
1473 else:
1474 # we by definition only have the 0th axis
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/indexing.py in _getitem_tuple(self, tup)
888 continue
889
--> 890 retval = getattr(retval, self.name)._getitem_axis(key, axis=i)
891
892 return retval
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/indexing.py in _getitem_axis(self, key, axis)
1866 return self._get_slice_axis(key, axis=axis)
1867 elif com.is_bool_indexer(key):
-> 1868 return self._getbool_axis(key, axis=axis)
1869 elif is_list_like_indexer(key):
1870
~/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/indexing.py in _getbool_axis(self, key, axis)
1496 return self.obj._take(inds, axis=axis)
1497 except Exception as detail:
-> 1498 raise self._exception(detail)
1499
1500 def _get_slice_axis(self, slice_obj, axis=None):
KeyError: MemoryError()