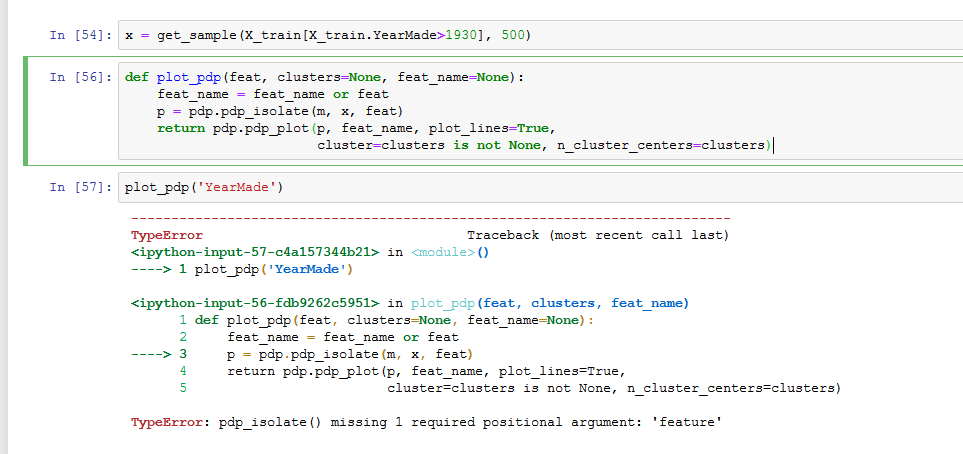
Hi Chamin,
I am running into this exact same problem, I have posted my notebook here.
Were you able to solve for this error?
Kind regards,
Luke
Hi Chamin,
I am running into this exact same problem, I have posted my notebook here.
Were you able to solve for this error?
Kind regards,
Luke
Hey Luke
I think firstly there is an error on In[15]. Im not quite sure what you are trying to do on this line.
I think the issue is that you did your proc_df() on df_test at the beginning - by the time you trained the most recent model on df_trn2 at In[37] the features will be larger due to the one hot encoding and other processing. If you check on your last line len(df_trn2.columns) I would expect it to be 250 columns long. You need to run your df_test through the same protocols you ran your df_train through to have the same columns at the end.
I hope that makes sense - the example in the Rossman from the DL1 course is good for demonstrating this.
Hi Kieran,
Thanks for taking a look, I will go through it in the next few days and see if that fixes it.
Cheers,
Luke
Hi,
df_trn, y_trn, nas = proc_df(df_raw, 'SalePrice', subset=30000, na_dict=nas)
X_train, _ = split_vals(df_trn, 20000)
y_train, _ = split_vals(y_trn, 20000)
In the above snippet, we get 30k random rows from df_raw which is of length 401125.
And I went on to see how it fetches 30k rows I found this code below fetches random 30k indexes
idxs = sorted(np.random.permutation(len(df))[:30000]) # in get_sample
Now, i’m confused why it’s not that the indexes which are in X_valid
def split_vals(a,n): return a[:n].copy(), a[n:].copy()
n_valid = 12000 # same as Kaggle's test set size
n_trn = len(df)-n_valid
raw_train, raw_valid = split_vals(df_raw, n_trn)
X_train, X_valid = split_vals(df, n_trn)
y_train, y_valid = split_vals(y, n_trn)
X_train.shape, y_train.shape, X_valid.shape
never picks up in the above idxs ?
As a result of which X_train has total different indexes as compared to X_valid.
Please correct me.
I have just completed Lesson 1, so I can’t be 100% sure but can you check what is the shape of X_Train too? Because that is the input dataframe for your model and not df_train. Ideally, they should be the same but just verify once.
I am looking at the code for add_datepart and I am confused about - What do these lines actually do?
First,
if isinstance(fld_dtype, pd.core.dtypes.dtypes.DatetimeTZDtype): fld_dtype = np.datetime64
Second,
df[targ_pre + 'Elapsed'] = fld.astype(np.int64) // 10 ** 9
Hello,
I am trying my first Kaggle Competition after the first lesson. I chose House Prices prediction.
I have tried to replicate all that was done in the first lesson on machine learning, but when I got to fit my model, I got a ValueError: n_estimators must be an integer, got <class 'pandas.core.frame.DataFrame'>.
I don’t understand what I did wrong or what more I should have done: shouldn’t the train_cats function take care of strings in the dataframe and convert them all automatically to numeric ?
You can verify the data types of your df by doing df.dtypes() and see if there are any non-numeric and non-categorical values.
Without seeing your code, it seems like you’re passing the pandas dataframe to the RandomForestRegressor constructor (the first argument is n_estimators and it expects an integer, but you’re giving it a dataframe). Remember that you first create the model and only with m.fit(X_train, y_train) you fit the model.
Hello,
In lesson 7, minute 17 a paper regarding resampling of unbalanced classes in training sets is mentioned. Could someone please help me find that paper (authors, title, or link)?
Thanks in advance for your help, and for this amazing set of lessons.
I think I found it in this other thread How to duplicate training examples to handle class imbalance.
Copying the link in case it is of interest for anyone else https://arxiv.org/pdf/1710.05381.pdf
Thanks.
Hi Utkarsh,
As I understood it its a fastai function which has been used to update the learning rate for optimisation of weights and biases,
I think min_sample_split is required to make sure you perform a split only if samples/rows/objects are greater than or equal to min_sample_split at current node. If any less is there then the split won’t happen. So if The max_depth is None and you have specified min_samples_split, the tree is not going to grow any further if the node contains less than min_samples_split samples/rows.
I second @jpramos reply. Try to name the parameters you are trying to send and hopefully it will resolve.
Hey Sashank,
I think it would be very simple to use categorical codes for random forests/ensemble/tree models and explain the results. If we use categorical codes in linear regression/logistic regression, the values assigned to categorical codes value may cause interference in building models. So wherever you are using decision/rule based models its OK to use categorical codes or one hot encoded variable. But when you are using anything other than rule/decision based algorithm I would suggest to use One Hot Encoding.
Hello,
I finished my first Kaggle competition and got a surprisingly good result for the dataset the first time I ran the model.
However, when I tried to separate the set in a training and a validation set, I have had worse results.
These are the results for the whole set:
[0.06640609395146409, 0.059749794949568814, 0.9724835235033371, 0.9731294015377561]
And those are the scores for the training and validation tests (I used a validation set of 43 rows, it’s roughly 0.02 percent of the whole set):
[0.06867925757638324, 0.15292615297037612, 0.9705674334979815, 0.8239775636830122]
By separating the set in a validation set and a training set, I fell well behind in the leaderboard (like in the 75%).
While using the whole set (I hope I didn’t make any mistake), it got me to the first place on the leaderboard.
Why is there so much difference in the predictions? Is it because my training set is too small to divide it up into two sets?
What’s the conclusion? Should you only divide your set when it is large enough?
Hi,
I recently started the ML part 1, and for that purpose created a GPU enabled GCP instance. But I realize that the course (at least the lesson 1) is only using the instance’s CPU.
What setting should I tweak in order to get the lesson 1 notebook execute cells using GPU ?
Also, following Jeremy’s request at the end of the lesson 1, I went to the first kaggle competition I could find and tried to prepare the data in order to run Random forest on it, but I’m facing a big issue:
While the video describes a dataset where each row has its own target value, the dataset I’m playing with has several rows per user, and the target to estimate is the log of the sum of a column for all rows grouped by user.
Now, to continue, I can only think of 2 options:
Can someone give me some pointers on the proper way to apply random forests on this competition ?
What do you mean by results from whole set? If you try scoring the whole set you will have only 1 RMSE and score value.
When you have two values that means there are two data sets - train and validation.
Without the code it is difficult to know what you did but if you are running jeremy’s code as-is then the second result happens after you sample the data. Jeremy had taken out 30k for faster processing.
Knowing how to clean/create your datasets for optimum models is one of the things we need to learn by doing multiple competitions. Jeremy covers some of these things in lesson 2 and 3.
But, if you really want to start on this competition you might want to think over why Jeremy had taken log of sale price in his example? My take is - It really simplified the explanation and the python notebook.
In reality, the log price is required only when we need to calculate RMSLE of our validation set. So instead of using the RMSE function:
def rmse(x,y): return math.sqrt(((x-y)**2).mean())
where x and y are log prices.
You can actually do:
def rmsle(x,y): return math.sqrt(((np.log1p(x)-np.log1p(y))**2).mean())
where x and y are normal (no log) prices.
Similarly in the Google competition you need log of user transaction but only during validation. So, run your rf as-is without logs. And when you need to check your predictions compare the log (sum of user transactions) in test and validation sets.