Thanks. The reason i was along whether ML course is complete or nott is because it had only 5 Notebooks.
Also, is doing the ML part necessary or can I skip to DL 1,2 because before ML was launched people were doing DL 1,2 in the beginning by default, right? I guess doing ML part provides better foundation for DL 1,2?
Also, how much time should I dedicate to each lecture,and apart from reading the notebooks , experimentation what else are we supposed to do? When should i assume that my 1st lecture material is complete ?
Thank you for the link
Just throwing in my two cents, but I don’t consider this a “must-do” course. As an example, I listened to all of the DL course 1 lectures straight through before going back and dissecting each lesson. When I went back, I started with whatever lesson I was interested in, listened for a while / took flashcards, then used it to refine something I had been working on (a Kaggle competition, solo research, etc.).
Each of us will have a unique style that teaches ourselves “the best”. Just jump in and enjoy the ride - don’t become the roadblock to your own enjoyment of the material!
2 Likes
Thanks
Are you in the fastai folder?
Did you activate fastai?
Follow the steps here
FASTAI
Hi @gerardo,
I’m running it in my local computer. Yes, I have followed the steps which are mentioned.
But still i’m facing the same issue.
Thanks,
Sumit
Do you have NVIDIA cards in your computer?
or are you using CPU only.
On the previous post there’s explanation of the CPU or GPU installation.
No.
Yes.
I’m trying to run lesson4-mnist_sgd (ML), I think it doesn’t require GPU?
Please correct me if I’m wrong.
Please Let me know if i’m doing it correct or not.
Initially When i started the course i have cloned the repo and i run jupyter notebook after which i used to run the cells and do the exp in notebook. But i never used activate cmd
Thanks,
Sumit
From fast.ai github repository
CPU only environment
Use this if you do not have an NVidia GPU. Note you are encouraged to use Paperspace to access a GPU in the cloud by following this guide.
conda env update -f environment-cpu.yml
Anytime the instructions say to activate the Python environment, run conda activate fastai-cpu or source activate fastai-cpu.
2 Likes
Thanks, @gerardo for all the help 
1 Like
In ML lesson 4 [6:30]. Jeremy indicated that when decreasing the set_rf_samples number, we are actually decreasing the power of the estimator and increasing the correlation. But I think the correlation should decrease right ? Because in this case, we are less likely to chose the same row for each individual tree.
Actually, he put a decreasing arrow but said increasing so I’m quite confused.
I’m sorry if the question is so basic, but there are some information in ML course quite hard for me to understand.
For set_rf_samples function. If the data set is not too big, we can quickly process the whole dataset, then should we use set_rf_samples ? or we build tree with all data. Or we try both to see the result because with subsample we have less correlation but less accurate for each tree.
1 Like
Very basic question. I ran proc_df() both on train data as well as test data but I am getting different columns numbers and thus I cannot run my model against the test data.
The only thing different that I can find is that for test data, it has 1 less column since that is the dependent variable/y value. I am using the data from a housing price Kaggle comp.
Let me what could cause the mismatch in column numbers! Thank you 
For those who might be encountering a similar issue… I found the solution in a another post here: Proc_df() for machine learning course
I successfully submitted results to Kaggle and ranked at 2882 out of 4379 entries
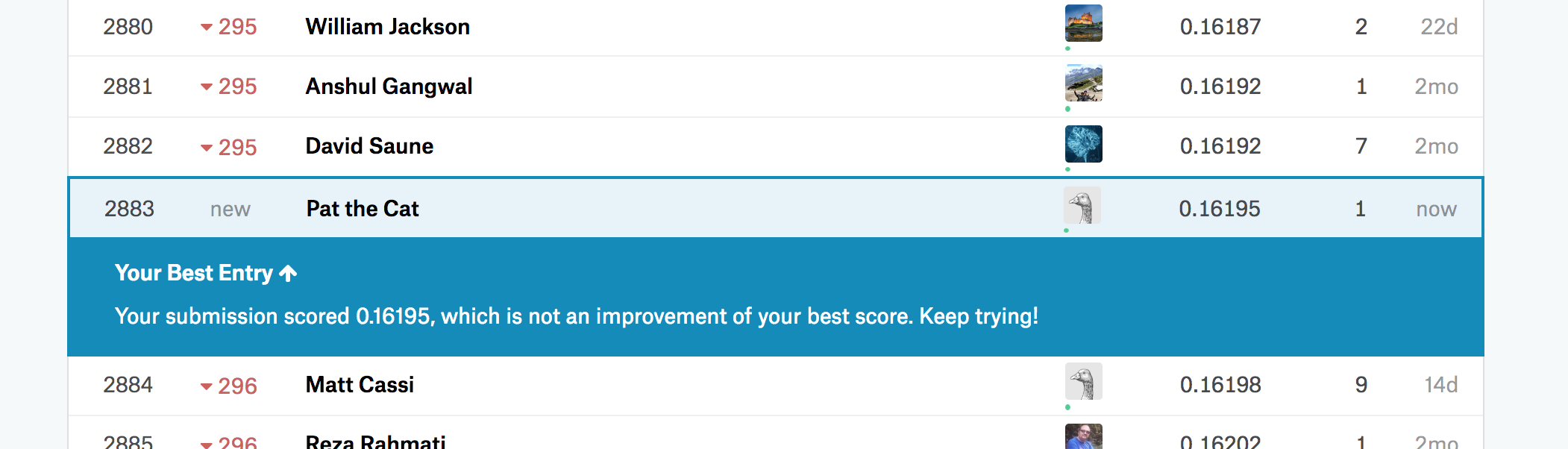
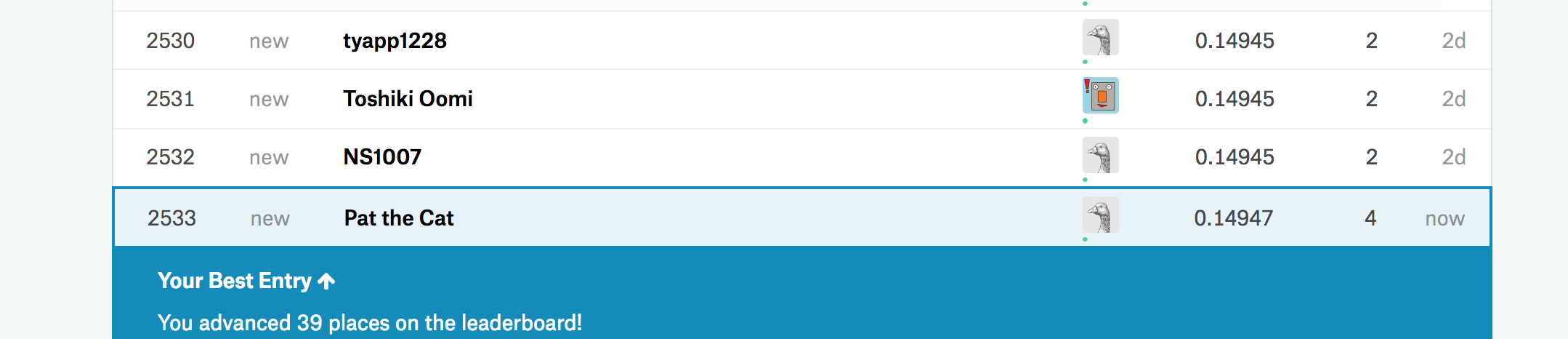
By using the concepts from week #2, I was able to move up by 300 ranks (from 2883 to 2533).
In RandomForestRegressor, if estimators>1, then what could be the size of each individual tree? How many train samples are considered for constructing each tree?
Size of the tree depends upon the max_depth . If max_depth =None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.
In lecture 8 , what does the function set_lrs do ?
The notebook says set_lrs(opt, 1e-2) .
I am getting the exact same issue using a paperspace GPU machine, with the "df, y, nas = proc_df(df_raw, ‘SalePrice’) " command. i have shutdown the paperspace instance a restarted a few times, and clearly restarted the kernel several times.
Anyone figure this out?
Shep