I just made some major changes to fastai. Would love help testing them out, getting comments, etc. They should fix some problems and open up some new options. To use it, git pull and then conda env update.
Most importantly, I’ve removed opencv entirely, and replaced it with PIL. All image transforms now receive a PIL object, not a numpy array. (@yinterian I haven’t tested whether any of your coords transform stuff is impacted. Note in particular I’ve changed how resize() behaves - I think the copying of the background probably needs to be optional to work with the coords code).
Since I removed opencv, that meant that I could go back to using pytorch’s DataLoader. This should therefore fix all memory problems that people have been having. It also reduces the GPU memory usage (opencv was setting aside some GPU memory for every process).
I’ve made a conda package containing pillow-simd, but I named it just ‘pillow’, and put it in a new ‘fastai’ channel, which the environment now makes the top priority channel. Therefore you should find your pillow lib gets replaced with the much faster pillow-simd version I created. I’ve compiled both MacOS and Linux versions.
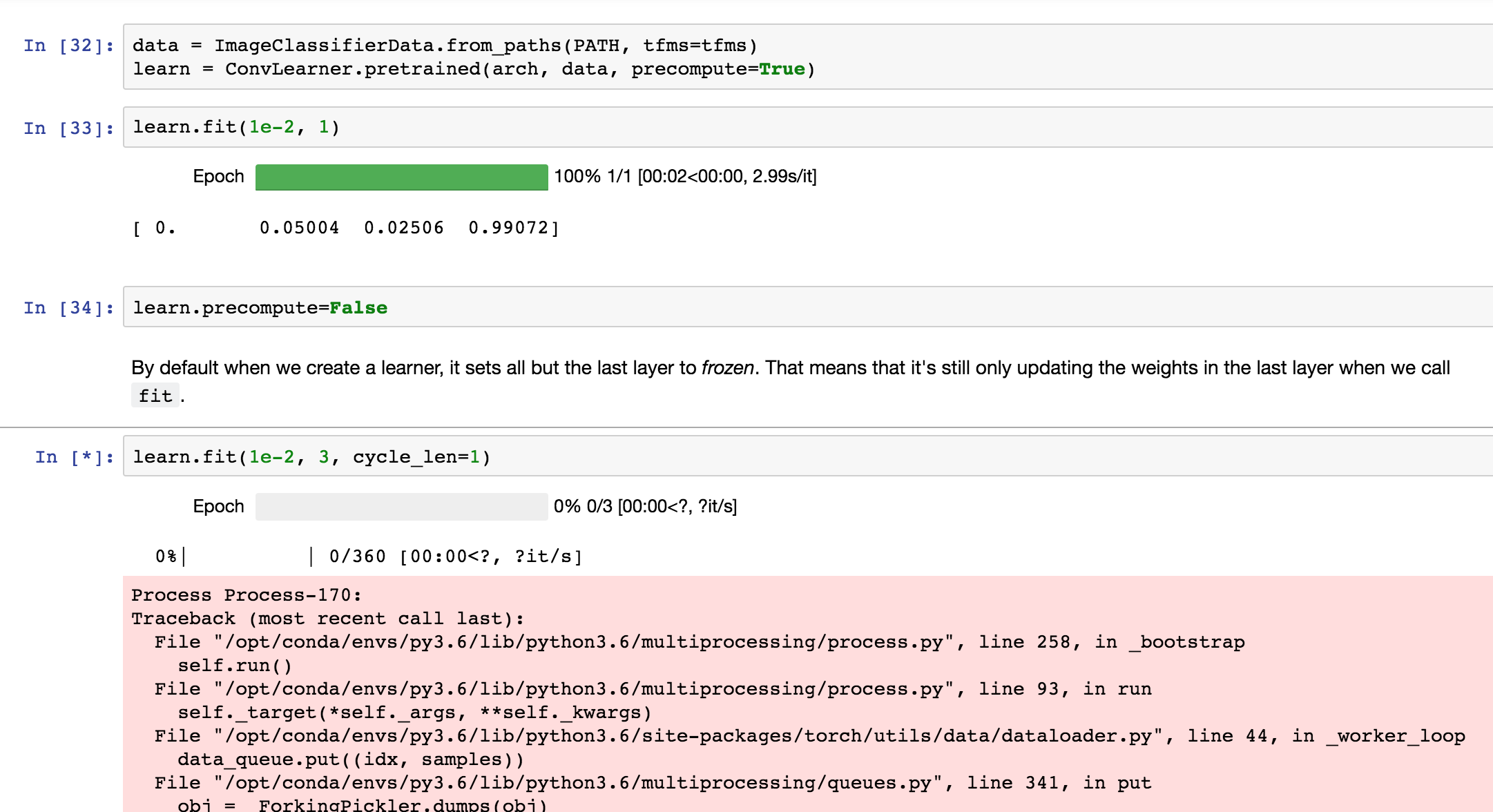
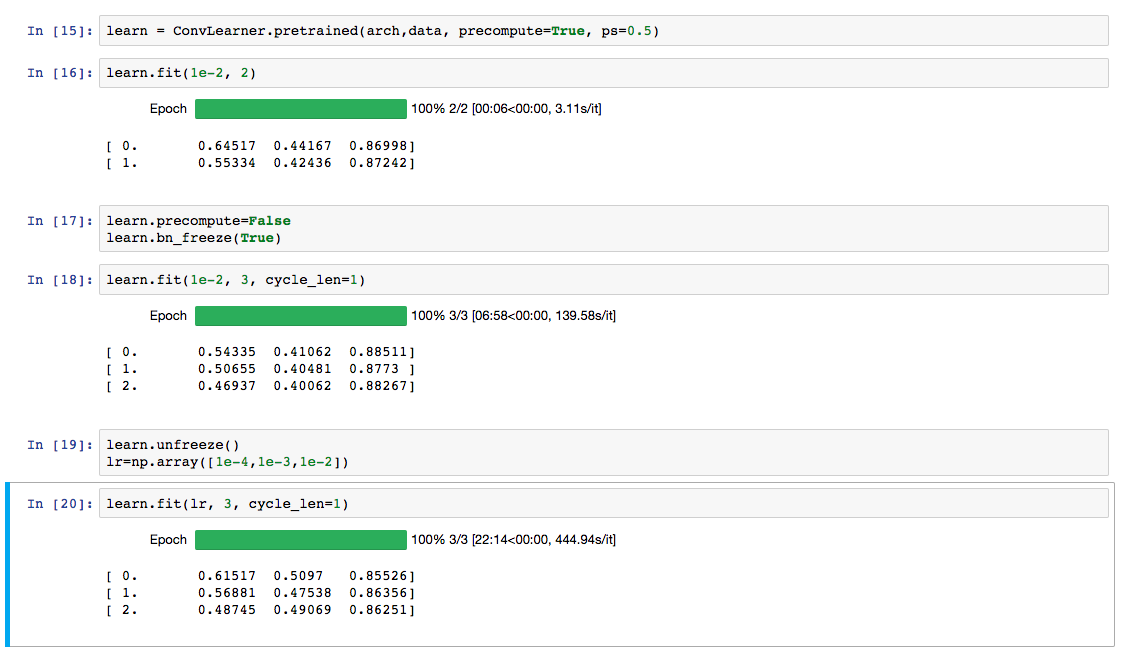
I discovered that inceptionresnet-v2 and inception-v4 were not training well on dogs v cats after unfreezing. I think I’ve tracked it down to an interesting issue with batchnorm. Basically, updating the batchnorm moving statistics causes these models to fall apart pretty badly. So I’ve added a new learn.bn_freeze(True) method to freeze all bn statistics. This should only be called with precompute=False, and after training the fully connected layers for at least one epoch. I’d be interested to hear if people find this new option helps any models they’ve been fine-tuning.
Finally, I’ve changed the meaning of the parameter to freeze_to() so it now refers to the index of a layer group, not of a layer. I think this is more convenient and less to learn for students, since we use layer groups when we set learning rates, so I think this method should be consistent with that.
Phew - that’s a lot! Don’t worry if none of this make sense to you - we’ll cover all these concepts in time. But feel free to ask if you’re interested in learning more about anything I’ve mentioned.