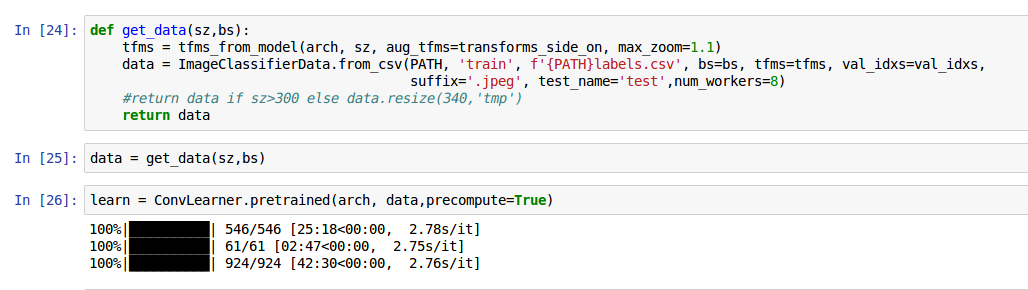
I am very interested in the Diabetic Retinopathy challenge on Kaggle. In essence, the main difference in the two challenges is that the first attempts to classify images of dogs into one of roughly 120 breeds, while the second classifies images of retinas into one of five stages of degeneration leading to blindness.
I have basically changed a line of code in the Dog Breed Jupyter Notebook to format the retina data in a consistent manner.
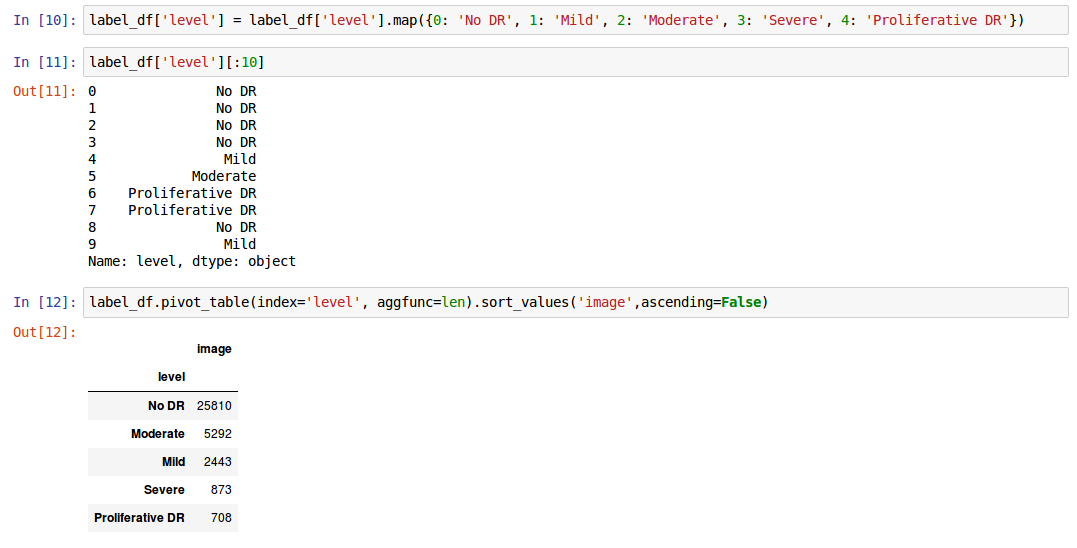
I’m running into an error near the end of the notebook. What seems to be happening is that the tmp file that the notebook creates to process a group of images at a time, seems to run into issues when working with a significantly larger number of images.
DogBreeds: Train = 10,222 / Test= 10,357 Images
Retina: Train = 35,126 / Test= 53,576 Images
The code seems to be looking for a specific image to analyze in the tmp folder that is not present at the time the system is trying to access it.
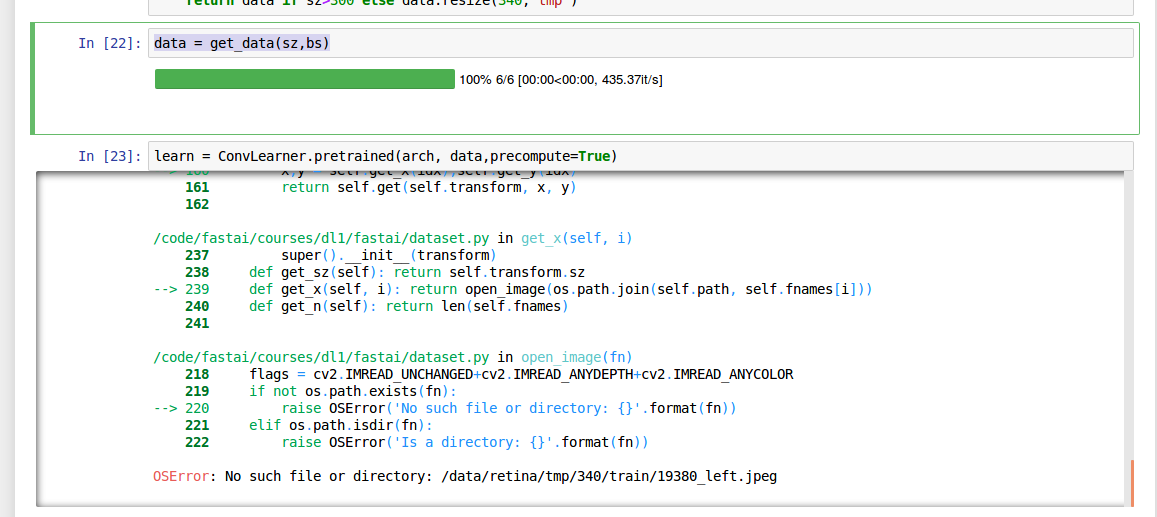
Now when I check the train folder, I discover that the image is in fact present.
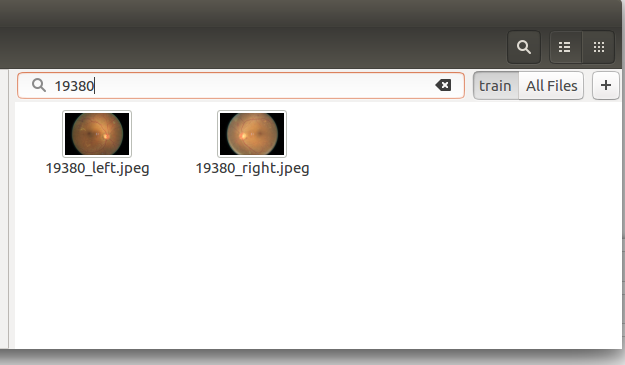
Inspired by this post, I decided to try deleting the tmp folder and setting val_idxs=None.
This lead to the line…
data = get_data(sz,bs)
Taking roughly 2 hours to load (Deep Learning Rig).
Do to the impracticality of that approach, for this dataset, I moved on to this post that seems to advocate for an approach to loading data based on using a percentage of the data. Based on which I changed val_idxs to the following:
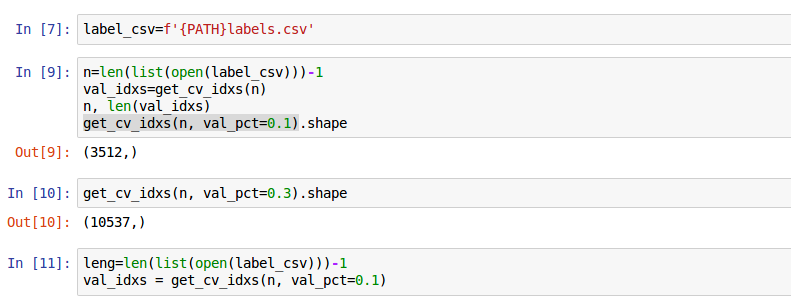
This, once again, resulted in an error involving tmp.
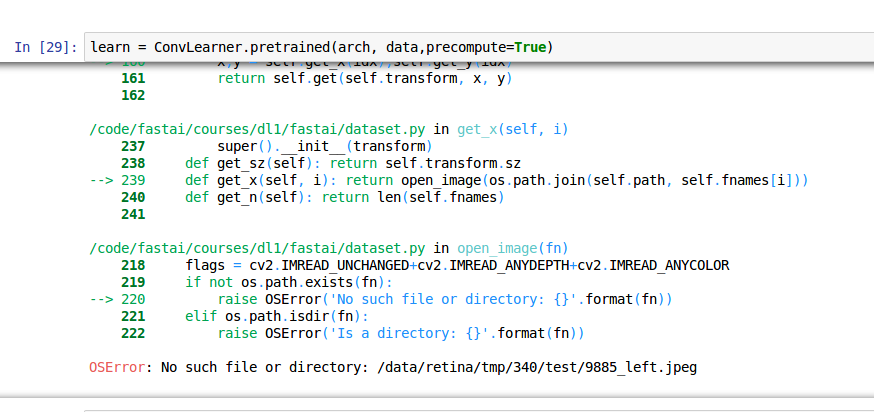
In all honesty, I am not really clear on how val_ixds works, even after reading a couple of forum posts on the subject. I do find it interesting that in my first example there was an issue locating part of the training set, while in the second, the issue was with finding an image in the test set.