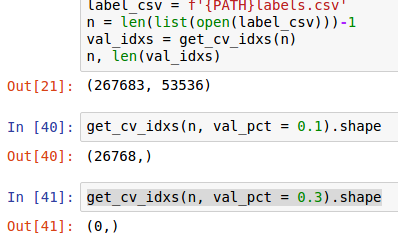
I am having some troubles in understanding how get_val_idxs() works. I have a super large dataset, and I do not want all the (half a million) samples to train, it gets painfully slow. I decided that I could assign more samples to the validation set, to make the training set less populated in a simple way. However, when I try to increase the parameter val_pct (the default is 0.2), i get back an empty list. This does not seem to happen when I call it with val_pct<0.2.
Worst thing, it does so silently, so you only realize once you have loaded all your data, resized it, and go through the activation precomputing stage. Here there is a screenshot showing this behavior:
Thanks for your quick answer! I can remember you did something like that sampling yesterday, but I have been looking for it in the video and in the notebooks, and cannot find that precise place.
This sampling must be done bat which point? After loading the data object with a call like:
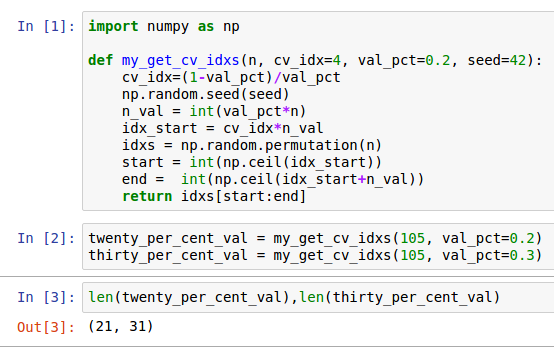
Well, not sure if the parameters inside the call to will be useful later in the course, but I ended up creating a simple version of this function that overrides the cv_idx parameter inside it. This can be used to create a validation set with the required percentage of samples on it, and it reproduces the behavior of get_cv_idxs for its default call:
Actually, I am not sure if the parameter cv_idx is useful for something else afterwards in the course (cross_validation?). If that is the case, the fact that I am over-writting it inside the function would not be a good idea. And if that is not the case, then it could even be removed from the arglist of the function… But I guess it is there for some reason we still do not know.
Absolutely. That’s why it only overrides when it’s not passed in with a val. I will leave the pull request for now…and let @jeremy or @yinterian comment on it as they might know all the places this function is called and its purpose.