I suspect something related to batch normalization. I think it differs for BN if it gets 2 images 16 times than getting 32 images. Maybe BN should be changed to something else like instance normalization or some other BN variant. But this is out of my territory. I hope Jeremy will chime in to help us out…
2 Likes
It seems BN is an issue here. If we would PR merge this callback as it is, but getting lower accuracy, I think that would not worth it. Maybe we can find how to remedy this BN issue. But it seems then we have to change the BN layers in the arch?
Most articles did not solve the BN issue when they showed how to do gradient accumulation, and they have not even mentioned it. I think that’s because they haven’t checked whether the accuracy they are getting are the same.
related:
3 Likes
Yes, BatchNorm will be problematic and I’m not sure there is a proper workaround.
@kcturgutlu I will try a few changes in the training loop that shouldn’t require the wrapper around the optimizer and allow to skip the step/zero_grad so that it can be all in a Callback
2 Likes
Ok, it’s pushed on master. Now, if you return True at the end of on_backward_end, the step is skipped, and if you return True at the end of on_step_end, the zeroing of the gradients is skipped. So if I take your current Callback, both should finish with:
return self.acc_batches % self.n_step == 0
5 Likes
Thanks a lot, I will modify the callback with the current changes.
1 Like
Being able to control independently and without any hardware restrictions,
- Effective batch size for all layers except BN
AND - Effective batch size for Batch Norm layers
would definitely be useful for many problems.
Most optimal size for 1) and 2) is likely not the same in a lot of problems/datasets.
In this paper they used the concept of ghost batch norm (https://openreview.net/pdf?id=B1Yy1BxCZ) to implement this control. But that is presumably a complex implementation linked to TPU management.
Technically, to solve 2), I guess we need a specific accumulation of BN activations (moving average during forward pass) and syncronized accumulation of gradients before parameters update specific to BN. But, to my understanding, accumulation of BN activations in forward pass in main memory would presumably be very slow and would counter most of the benefit of using the GPU at all.
5 Likes
I modified the callback and updated the current PR. Here is a test with a custom head which doesn’t use BN and uses vgg11.
Effective bs = 32 and bs=2 x n_step=16 very similar results.
It would be really cool to do accumulation and handle BN layers. What if we create a wrapper over all BN layers at the beginning of training and maybe do forward every n_step while keeping track of desired running_mean and running_var ourselves. Would something like this work?
1 Like
Yes, a wrapper around the batchnorm layer would probably best. We might lose speed though, since there might be some optimization in pytorch for this. Might be possible to counter with torch.jit, I’ve just started to experiment with it to do quick custom LSTMs and it seems quite nice.
In any case, we removed all batchnorm in the unet with Jeremy because it was soooo unstable with small batch sizes so I’m pretty sure that it’s the cause of your differences in accumulating grad.
4 Likes
Would love to see some code once it’s available. In mean time I might try to see what is the most optimal way to handle BN layers.
Group Normalization may be of interest here. The paper reports stable performances independent of batch size:
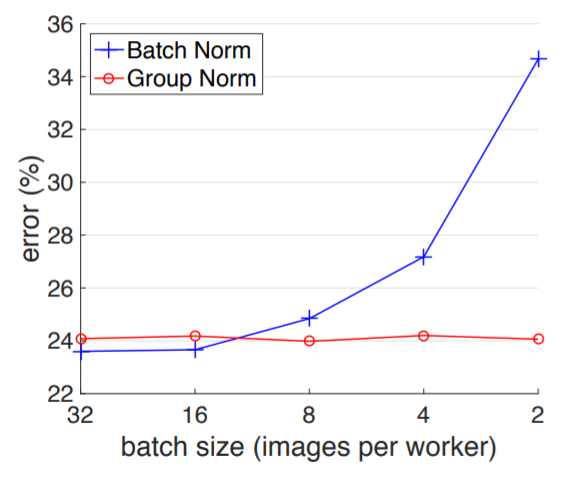
4 Likes
That’s very cool! The reason I am interested in BN is to utilize many pretrained models.
Thanks for the paper!
Here is the blog post of that paper:
1 Like
Would just changing bn momentum largely fix the difference when using grad accumulation?
4 Likes
The 3rd winning solution code for the Human Protein Atlas comp is released. He used gradient accumulation. Trying to figure out how he handled the BN issue:
- For the large model with 1024x1024 images, I used gradient accumulation so that weights are updated every 32 examples.
3 Likes
I believe he normalized every image to itself before sending it through the network.
I am intending to give this a try with the notebooks that have been posted here, but I’m not sure how quickly I will be able to post results.
Changing BN momentum is an interesting option to fix the learnable BN parameters Gamma and Beta. But the running mean/variance would not be modified by changing momentum. BN benefit is presumably related partially to the learnable parameters and partially to the running mean/variance. Intuitively, the relative contribution of each probably depends on input variability, label noise, raw batch size and network depth.
1 Like
Yes, I noticed that too… But does that mean BN would be effectively the same with small or large batch sizes? Did he mitigate the BN issue by doing so?
And doing normalization for each individual image seems weird to me… This would diminish the individual variations of the image features including the interesting feature differences that we want to use for classification… By doing so all colors will look almost the same (within the same color channel)… We will not be able to differentiate different shades of greens for example…
Let’s say you are classifying different types of green grass… We will lose the important color information by doing individual image normalization…
2 Likes
I agree that it seems weird, and I see no error in your reasoning. But it’s all weird to me. The group norm paper shows that normalizing small batches is worse normalizing larger batches, but normalizing to the whole dataset also does not seem optimal, I don’t know why. In any case I’ll give the single image normalizing a shot.
1 Like
Maybe we can benchmark using this dataset. Thanks!