OK thanks for the quick reply, it is good to know the gradient accumulation suggestion fits fine with other existing callbacks. May be my expectation of the fbeta metric of a 256 batch size run to match the 128 batch size with optimizer step every other batch in the same number of total epochs is incorrect. I need to figure out a way of validating my gradient accumulation code changes are error free in some other way.
Any chance to include accumulating gradients into fastai?
A solid method for gradient accumulation in fastai v1 would be good for everyone.
2 Likes
I think @kcturgutlu 's method is fine and it should be properly working. If he wants to make a PR out of it to make it easier to use, that would definitely be welcome.
3 Likes
I can gladly create a PR if there is enough request for such a feature  My only concern is we might need some minor changes to make sure gradients accumulated this way is mathematically equivalent to the gradients by calculating the loss with all accumulated batches. I will investigate this and then do a PR.
My only concern is we might need some minor changes to make sure gradients accumulated this way is mathematically equivalent to the gradients by calculating the loss with all accumulated batches. I will investigate this and then do a PR.
Similar thread in PyTorch forums: https://discuss.pytorch.org/t/why-do-we-need-to-set-the-gradients-manually-to-zero-in-pytorch/4903/20
I did some test, grad calculations are only equal if reduction=sum of loss function, but we often use reduction=mean. The reason is average of a collection of numbers is not equal to sum of average of parts of those numbers. We might need to handle cases when loss function reduction=sum and reduction=mean. But I don’t know if handling this practically improves the performance.
Solution is to enforce reduction=sum in loss function, then keep track of number of samples in accumulated batches and do params.grad.div_(n_samples) before learn.opt.real_step().
This way runtime will be longer than usual backprop but theoretically one can fit infinite size batch sizes given any memory constraint. Since we will release computational graph after each .backward()
6 Likes
@sgugger need some help here
So I created a callback which will handle the above issues but I don’t know how to best integrate monkey patching in terms user experience.
Here is the implementation:
class AccumulateOptimWrapper(OptimWrapper):
def step(self): pass
def zero_grad(self): pass
def real_step(self): super().step()
def real_zero_grad(self): super().zero_grad()
def acc_create_opt(self, lr:Floats, wd:Floats=0.):
"Create optimizer with `lr` learning rate and `wd` weight decay."
self.opt = AccumulateOptimWrapper.create(self.opt_func, lr, self.layer_groups,
wd=wd, true_wd=self.true_wd, bn_wd=self.bn_wd)
@dataclass
class AccumulateStep(LearnerCallback):
"""
Does accumlated step every nth step by accumulating gradients
"""
def __init__(self, learn:Learner, n_step:int = 1):
super().__init__(learn)
self.n_step = n_step
def on_train_begin(self, **kwargs):
"check if loss is reduction"
if self.loss_func.reduction == "mean":
print("For better gradients consider 'reduction=sum'")
def on_epoch_begin(self, **kwargs):
"init samples and batches, change optimizer"
self.acc_samples = 0
self.acc_batches = 0
def on_batch_begin(self, last_input, last_target, **kwargs):
"accumulate samples and batches"
self.acc_samples += last_input.shape[0]
self.acc_batches += 1
print(f"At batch {self.acc_batches}")
def on_backward_end(self, **kwargs):
"step if number of desired batches accumulated, reset samples"
if (self.acc_batches % self.n_step) == 0:
for p in (self.learn.model.parameters()):
if p.requires_grad: p.grad.div_(self.acc_samples)
print(f"Stepping at batch: {self.acc_batches}")
self.learn.opt.real_step()
self.learn.opt.real_zero_grad()
self.acc_samples = 0
def on_epoch_end(self, **kwargs):
"step the rest of the accumulated grads"
self.learn.opt.real_step()
self.learn.opt.real_zero_grad()
Thanks !
4 Likes
I did a minor experiment to see if this actually helps at any circumstance.
data: MNIST
Experiment 1
I tried using bs=32 without accumulation and bs=8 + n_step=4 with accumulation. So effective bs in both cases are 32. Both with fit(4)
Without accumulation convergence is faster and performance is ~ 0.975+0.01-0.015 better but still close.
Experiment 2
Used bs=4 without accumulation and used bs=4 and n_step=8 to mimic a use case where resources are limited to bs=4. In this setting model training without accumulation
is not very stable stands around 0.86 whereas accumulation performance is 0.905 with same number of epochs.
Training time - no accumulation: 3:25 min
Training time - accumulation: 2:25 min
Batch size is a very experimental hyper parameter I guess but still accumulation might help with cases where resources are very low for a given task. Would be interesting to see how it acts with 3D conv nets, where 1-2 samples per batch hardly fits to an average GPU.
I am adding these functions to train.py as an easy solution for now:
original_create_opt = Learner.create_opt
def turn_off_accumulation(): Learner.create_opt = original_create_opt
def turn_on_accumulation(): Learner.create_opt = acc_create_opt
7 Likes
This is so cool @kcturgutlu
Thanks for your contribution to the fastai community.
How much was the change in accuracy in experiment 1. Theoretically, it should be the same if we ignore the small random noise.
Btw, you have assigned a seed for databunch to make train split consistent, right?
I have seen that sometimes when I repeat the run, there will be some accuracy fluctuations.
3 Likes
I used:
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
But I am not 100% sure it ensures to seed everything.
5 Likes
Ha, That’s way more seeds than what I thought…
How much was the change in accuracy in experiment 1?
I can create a notebook and share but I am bit busy now. But please feel free to try out yourself.
1 Like
I will do…
I will try it on the pet notebook lesson1
1 Like
It’s my pleasure contributing and I am happy to be contributing since fast.ai library has such a powerful callback system, very easy to use. Thanks to all devs !
2 Likes
By the way currently if you call lr_find it resets to originalOptimWrapper. Don’t know why but investigating. A work around:
def get_learner():
turn_on_accumulation()
learn = create_cnn(data=data, arch=models.resnet101,lin_ftrs=[2048], metrics=accuracy,
callback_fns=[partial(AccumulateStepper, n_step=25)])
learn.loss_func = CrossEntropyFlat(reduction="sum")
return learn
learn = get_learner()
learn.lr_find() # pick lr
learn = get_learner()
1 Like
Here are the notebooks that I am testing now:
| github links: | ||||
|---|---|---|---|---|
| lesson1-pets-v13-grad-accum-OFF-fp32.ipynb | https://github.com/hwasiti/fastai-course-v3/blob/master/nbs/dl1/lesson1-pets-v13-grad-accum-OFF-fp32.ipynb | |||
| lesson1-pets-v13-grad-accum-ON-fp32.ipynb | https://github.com/hwasiti/fastai-course-v3/blob/master/nbs/dl1/lesson1-pets-v13-grad-accum-ON-fp32.ipynb | |||
| lesson1-pets-v13-grad-accum-OFF-fp16.ipynb | https://github.com/hwasiti/fastai-course-v3/blob/master/nbs/dl1/lesson1-pets-v13-grad-accum-OFF-fp16.ipynb | |||
| lesson1-pets-v13-grad-accum-ON-fp16.ipynb | https://github.com/hwasiti/fastai-course-v3/blob/master/nbs/dl1/lesson1-pets-v13-grad-accum-ON-fp16.ipynb |
I will do a statistical comparison and will report the analysis here shortly.
Please have a look on them and confirm whether they are fine.
Thanks
1 Like
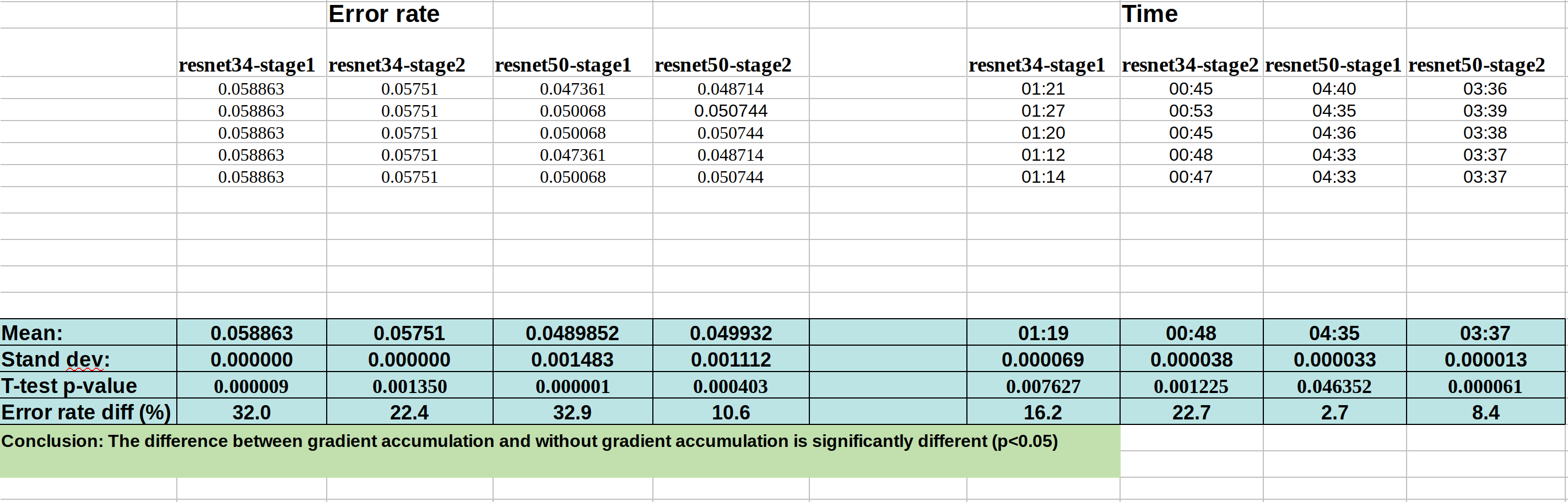
Here is the data for running the FP32 notebooks (with or without gradient accumulation):
Without grad accum.:
With grad accum.:
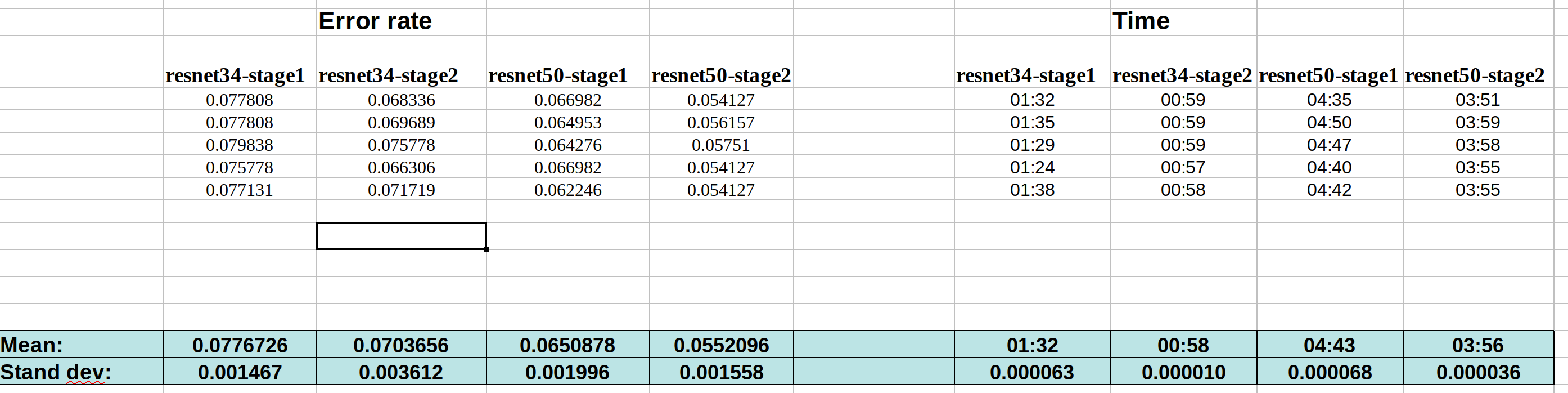
My intention was to run each notebook 10 times. But from the data, I can see that seed is indeed working perfectly. And there are only tiny variation from run to run within each method.
So the change in the error rate after applying those callbacks is ~25% on average, which cannot be explained by the noise of variation from run to run.
@jeremy
Kerem is going to make a PR request for gradient accumulation with the help of @sgugger . It seems from my analysis above that there is significant difference in the accuracy of doing gradient accumulation of 4 steps with bs=8 (i.e., effectively bs=32), compared to a normal run with bs=32. The difference in error rate is ~25%.
I’ve listed the notebooks used in my previous posts.
Just to be sure before doing the PR, do you think, there is something missing in these callbacks? Isn’t it that we should expect the same error rate in both cases?
1 Like
Have you tried fit or fit_one_cycle. Maybe since learning rates will differ during the training, fit_one_cycle might be causing this difference ? Will look closely.
I used the same lesson1 notebook without changes. You can have a look on the notebooks in the github links in my previous post.
Any factor (other than what we have introduced, i.e., gradient accumulation) if it has effect from run to run, it would show that variability inside the repetitions of the same group. But we can see from the chart that it is very nicely consistent if we check only the without grad accum. or check only the with grad. accum. group.
I see, thanks for the experiments. I will conduct more analysis to see why same effective batch sizes might be giving different results. For example, at very extreme bs=2 n_step=16 bs=32 is far from the same performance of bs=32 without accumulation. Technically this shouldn’t be the case!
I am guessing this might be something to do with the optimizer.
1 Like
Here is a Pytorch implementation of gradient accumulation:
1 Like
The way I implemented using reduction=sum + params.grad.div()_ works on a Toy example and I am getting the exact same gradient weight updates, both with and without accumulation. The reason we are getting different results by using it as a callback might be a subtle thing which is not related to accumulation but more likely to optimizer.
Here is the toy notebook: https://github.com/KeremTurgutlu/whale/blob/master/Accumulating%20Grad.ipynb