I have a custom batch sampler that I am training with but I also want to accumulate the gradients and do weight updates only at the end of each epoch but not each batch. What would be the most fastai way to do this with minimal effort. Thanks !
4 Likes
You’re asking for the one thing not possible in the library, congrats for finding it 
More seriously I think the only way is to rewrite your training loop in this case. fit and loss_batch are the two functions to look for.
Otherwise fancy way I see is to write a custom OptimWrapper that won’t step or zero_grad directly (for now it delegates to the pytorch optimizer) but rather when you call another function (like step1 and zero_grad1).
Thanks a lot for the quick reply let me take a look into your suggestions. It was just the sake of trying out something I had in my mind  There might be possibly ways of hacking way around as well. Thanks again !
There might be possibly ways of hacking way around as well. Thanks again !
Out of curiosity can you explain why, for the rest of us? I’m interested…
I am trying to train a classifier with 5005 classes for the this competition . The goal is to identify images of whales but training data is very limited, in some cases you only have 1-5 images per whale among 20k+ images. (I am 100% sure there would be a more complete thread about this competition in the forums)
At first look one shot learning seems like the way to go with this type of task but other’s also yielded good results with oversampling by duplicating the images. For me this is equivalent to writing a custom sampler which will sample minority classes more frequently and since we apply transforms on the fly we won’t memorize the minority classes.
What I want to do, though I don’t know if it’s mathematically viable, is to accumulate gradients until forward pass is done with approximately every class. Say bs = 128, when we sample 1 image from random 128 classes we get one batch. It feels like with this sampling method if I do my updates every batch it will be really hard for model to learn the decisions boundaries for every class - almost like refreshing the weights of the model at each update since every batch approximately have a different class set (I tried batch updates with this sampler and it was way worse than random sampling as I suspected).
Epoch updates is of course experimental I don’t know whether it would work.
For example decision boundaries obtained by softmax - MNIST:
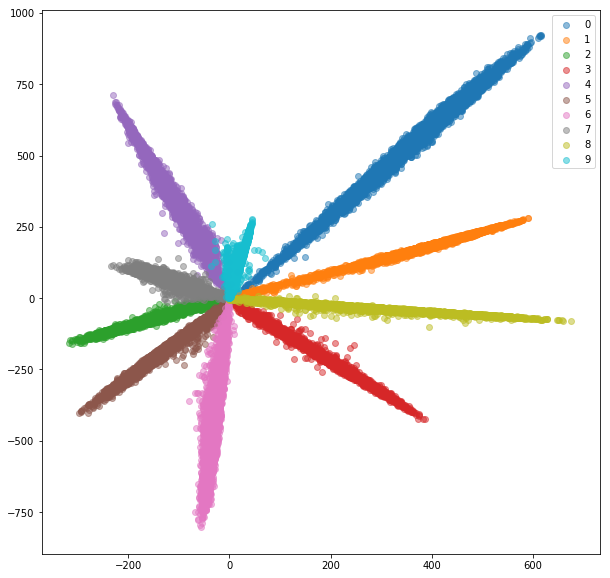
For example decision boundaries obtained by few shot learning embeddings: - MNIST

To those who are interested 2 good sources for starting off with this competition:
- @radek’s starter kit
- Playground winning solution
1 Like
There is a thread, but Jeremy asked that we move it to the Kaggle forums out if respect. Interesting idea Radek’s stuff is definitely the best public information out there. My “advanced” idea is very different than yours, but if it doesn’t work I’m going to go after one shot.
Good luck!!!
Good luck to you too
Followup – You said 5005 and not 5004… Tell me more 
Yeah…probably excluding new_whale class is a better approach, 5005 is just sake of experimenting with the most baseline way.
Just gave it more thought, and the OptimWrapper thing is the more elegant. It’s not tested or debugged, but something like
class myOptimWrapper(OptimWrapper):
def step(sellf): pass
def zero_grad(self): pass
def real_step(self): super().step()
def real_zero_grad(self): super().zero_grad()
should work with two changes:
- monkey_patch
Learner.create_optto usemyOptimWrapperand notOptimWrapper - call
learn.opt.real_step()andlearn.opt.real_zero_grad()when you want to do it.
1 Like
Thanks a lot for helping out ! I will definitely try and test it on a simple example. Happy holidays btw 
I guess I can use this custom optim wrapper and call real step and real zero grad on_epoch_end. I guess you were a bit wrong and anything is possible with fastai + callbacks  Thanks again
Thanks again
1 Like
Hopefully for very large classes this will alllow more stable training which minimizes well in trade of a longer training compared to our default batch step.
Edit: Solution found it’s as below for anyone in future:
Step 1) Bypass original step and zero_grad. Implement copy of these methods:
class myOptimWrapper(OptimWrapper):
def step(self): pass
def zero_grad(self): pass
def real_step(self): super().step()
def real_zero_grad(self): super().zero_grad()
Step 2): Implement another callback to call new real_step and real_zero_grad methods at the `on_epoch_end():
@dataclass
class StepEpochEnd(Callback):
learn:Learner
def on_epoch_end(self, **kwargs):
print("real step and zero grad")
self.learn.opt.real_step()
self.learn.opt.real_zero_grad()
Step 3): Optionally do sanity check and check weights and grads before each batch and after each epoch:
@dataclass
class ShowGrads(Callback):
learn:Learner
def on_loss_begin(self, **kwargs):
print("before batch loss:")
last_layers = self.learn.layer_groups[-1]
last_layer = last_layers[-1]
print(last_layer.weight)
print(last_layer.weight.grad)
def on_epoch_end(self, **kwargs):
print("on epoch end:")
last_layers = self.learn.layer_groups[-1]
last_layer = last_layers[-1]
print(last_layer.weight)
print(last_layer.weight.grad)
Step 4) Monkey patch optimizer creation:
def my_create_opt(self, lr:Floats, wd:Floats=0.)->None:
"Create optimizer with `lr` learning rate and `wd` weight decay."
self.opt = myOptimWrapper.create(self.opt_func, lr, self.layer_groups,
wd=wd, true_wd=self.true_wd, bn_wd=self.bn_wd)
Learner.create_opt = my_create_opt
6 Likes
I think you missed a step to make the Learner use this MyOptimWrapper class.
That’s right let me add it to thread. Thanks
Will this way interfere with fp16 or one-cycle callback handler? I tried to repurpose this for my use case where I want to do gradient accumulation for multiple batches, so that I can update the weights after more batches than my GPU can hold but I see the fbeta metric does not match to the value I get when I can fit with a larger batch. For my test case here is the result after 10 epochs. I understand there will be some randomness but I ran multiple times and the individual numbers are more or less consistent.
batch size. : fbeta
128 : 0.455298
256. : 0.477759
128 update weights every 2 batches: 0.4520
Here is the code, I am using.
# Gradient accumulation wrapper, Accumulate gradient and run optimization step every n batches.
class myOptimWrapper(OptimWrapper):
n = 2
istep, izero_grad = 1, 1
cnt = 0
def step(self):
if self.istep == self.n :
super().step()
self.cnt += 1
self.istep = 1
else :
self.istep += 1
def zero_grad(self):
if self.izero_grad == self.n :
super().zero_grad()
self.izero_grad = 1
else :
self.izero_grad += 1
def my_create_opt(self, lr:Floats, wd:Floats=0.)->None:
"Create optimizer with `lr` learning rate and `wd` weight decay."
self.opt = myOptimWrapper.create(self.opt_func, lr, self.layer_groups,
wd=wd, true_wd=self.true_wd, bn_wd=self.bn_wd)
Learner.create_opt = my_create_optI even tried repurposing basic_train.fit and loss_batch but ended up with the same result.
def myFit(epochs:int, model:nn.Module, loss_func:LossFunction, opt:optim.Optimizer,
data:DataBunch, callbacks:Optional[CallbackList]=None, metrics:OptMetrics=None)->None:
"Fit the `model` on `data` and learn using `loss_func` and `opt`."
cb_handler = CallbackHandler(callbacks, metrics)
pbar = master_bar(range(epochs))
cb_handler.on_train_begin(epochs, pbar=pbar, metrics=metrics)
exception=False
try:
for epoch in pbar:
model.train()
cb_handler.on_epoch_begin()
cnt = 0
NBATCH = 2
for batch_idx, (xb,yb) in enumerate(progress_bar(data.train_dl, parent=pbar)):
xb, yb = cb_handler.on_batch_begin(xb, yb)
#loss = loss_batch(model, xb, yb, loss_func, opt, cb_handler)
###################################################
if not is_listy(xb): xb = [xb]
if not is_listy(yb): yb = [yb]
out = model(*xb)
out = cb_handler.on_loss_begin(out)
if not loss_func: return to_detach(out), yb[0].detach()
loss = loss_func(out, *yb)
loss = cb_handler.on_backward_begin(loss)
loss.backward()
cb_handler.on_backward_end()
if opt is not None and (batch_idx+1)%NBATCH == 0:
cnt += 1
opt.step()
cb_handler.on_step_end()
opt.zero_grad()
loss = loss.detach().cpu()
if cb_handler.on_batch_end(loss): break
print('Total opt step = ', cnt)
if data.valid_dl:
val_loss = validate(model, data.valid_dl, loss_func=loss_func,
cb_handler=cb_handler, pbar=pbar)
else: val_loss=None
if cb_handler.on_epoch_end(val_loss): break
except Exception as e:
exception = e
raise e
finally: cb_handler.on_train_end(exception)
basic_train.fit = myFitFP16 support has helped me a lot in training larger images, thanks for that feature. Providing support for gradient accumulation will help even more for use cases like mine where we train on commodity GPUs with limited memory like RTX/GTX(as opposed to V100). I am open to working on it or testing it if you need my help and agree it is worthwhile.
It won’t interfere with FP16. For the one_cycle, it’s just going to pick the learning you are are each time you iterate, but it’s still going to be updated every batch, so you are going to follow the same curve and it should work the same (you’re just keeping one point out of two if you update every two batches).