What do you mean by how much was set? Layer 1 has a nn.Linear layer of 1000 neurons, and another that is 500 neurons
So what i meant was can i for instance do [800, 200]? Or is there an intuition to follow?
Sure! You can use any architecture size you wanted ! You could even do something like so (though I personally wouldn’t recommend it):
layers = [1000,900,800,700......,100,10]
I generally follow how Jeremy does his (they work pretty darn good!) If I have a ton of variables, 1000,500, if there’s only a few (<20) I’ll do the 200,100, but it’s certainly something to play around with 
The key with the tabular models is to be small and quick so between 2-3 layers of size depending on the dataset/what seems to be working. If you’re overfitting, perhaps try bringing it down a little
1 Like
This should have been done for Adults notebook as well right?
That’s what we’re referencing out of, yes. I updated it.
I faced an error on running the following snippets of code in categorical encoding challenge in Kaggle. Any idea what is the issue?
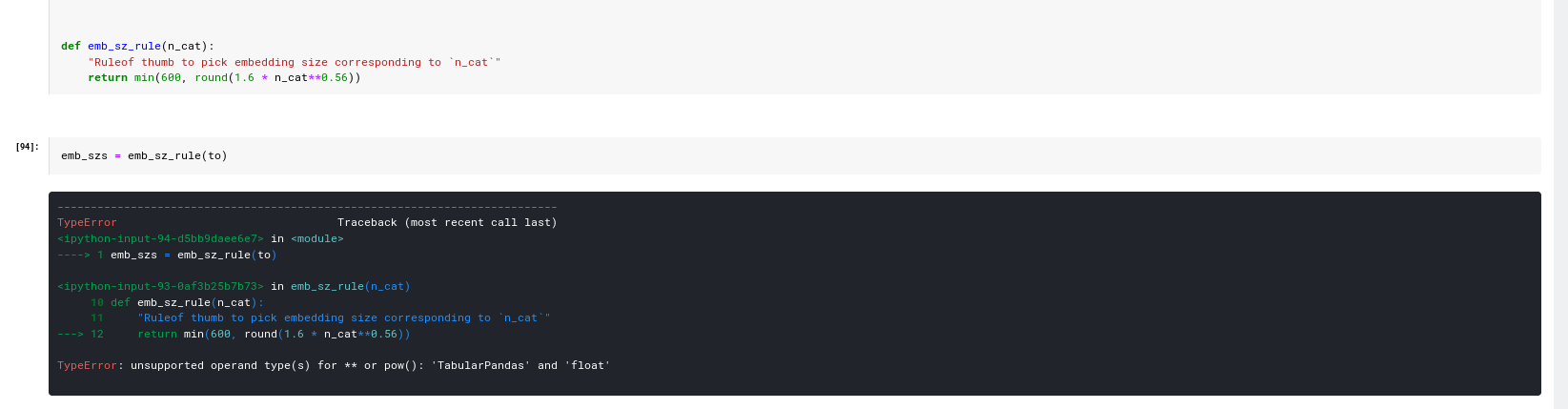
What version of pandas
print(pd.version)
0.25.3
Does it work only with pandas 1.0?
In the notebook of permutation Importance algorithm:
Should we download all the output files from https://www.kaggle.com/init27/fastai-v3-rossman-data-clean/output or just the df folder?
Just the train_clean and test_clean (the output)
1 Like
On running the notebook Permutation Importance, and submitting it to Rossman competition. The submission is able to get a score in private LB of rank 125(clearly in silver medal position).
When is the next session @muellerzr?
I’m going to try for early this week, what day I do not know, being sick and with the new course everything has kinda been thrown off kilter. I’ll have to see. If I do it’ll be a much shorter lecture (<1hr) or do it in batches. (as for those who do not know, I am currently sick with an upper respiratory infection)
Worst case presume it’ll be similar to the large post I did a little bit earlier. I just worry about speaking for so long
2 Likes
@muellerzr I am reviewing 02_regressioand_and_permutation and I was wondering why are you doing idx = train_df['Date'][(train_df['Date'] == train_df['Date'][len(test_df)])].index.max()
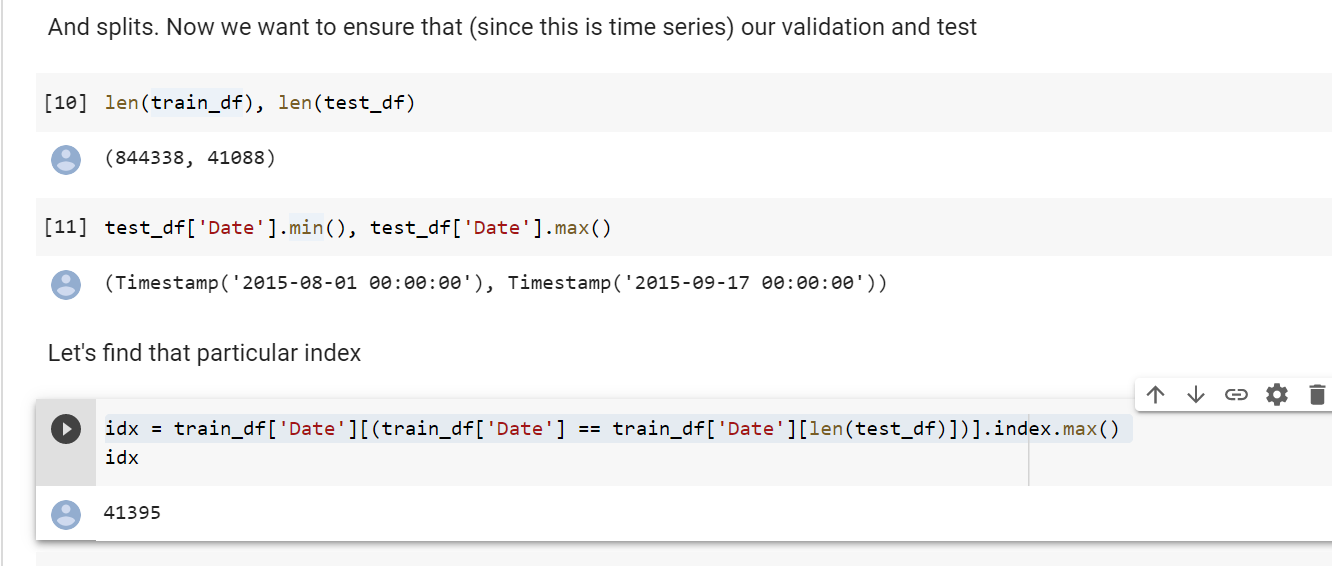
Which index are you trying to get here? Then you do splits = (L(range(idx, len(train_df))),L(range(idx))) to create (I guess the training and validation split) but I do not understad the logic. How did you choose the timestamps for each?
This is based on jeremy’s lesson actually. The idea is to have the validation set be the same time range (in # of days) as the test set. And also to have it be just the last n days as well (closest to the test set). If that’s confusing let me know and I can try again ![]()
1 Like
Awesome @muellerzr ! How can we create our own metric?
learn = tabular_learner(dls, layers=[1000,500], ps=[0.001, 0.01],
embed_p=0.04, y_range=y_range, metrics=exp_rmspe,
loss_func=MSELossFlat())
I checked out the function code here. but I do not get why AccumMetric() is necessary… my wish was to implement Weighted Root Mean Squared Scaled Error (RMSSE)
def _exp_rmspe(inp,targ):
inp,targ = torch.exp(inp),torch.exp(targ)
return torch.sqrt(((targ - inp)/targ).pow(2).mean())
exp_rmspe = AccumMetric(_exp_rmspe)
My second question, from the permutation part, is what do you mean by ‘shuffling’? Are you changing the order of the embedding columns…? What are you exactly shuffling by a percentage? (really cool btw, to know about this interpretability technique)
All metrics in fastai need them as we use a decodes method that’s nested inside of it. (Remember how I said transforms are everywhere?)
Is there a sklearn implementation?
Exactly what it sounds like. I’m literally taking an entire column, and (for visualization sake) putting them into a hat. Then I grab randomly from said hat putting them back one by one (but they’re not in the same order now)
For how/what it is, look into the np.random.(something, I’ll edit this later) function that is called to shuffle the columns
Actually, here. I’m feeling a bit better right now. I’ll go live in say 10 minutes and we’ll do a walkthrough to get the ideas down verbally ![]()
@muellerzr do we have a tabular walkthrough today ?
Correct we’ll go over the one from last week (as I’m more prepared for it) IE regression, permutation importance, etc. I’ll share the link here in a moment (FYI @mgloria so you’re aware too!)
1 Like
sounds good