Just site either myself (I’m on Kaggle), or point to the GitHub notebook it’s based off of 
1 Like
As I’m going through, I decided to adjust the topics as I believe this flows better. Also, I’m feeling better and can manage the time so for a fact we will have lesson 2 on Thursday (yes with lesson 3 on Saturday!)
So tommorow, we’ll be going over: Regression, Permutation Importance, Bayesian Optimization, and Ensembling with other model types. Here’s the link:
1 Like
Is this issue fixed now? Also where should I set reduce_memory=False?
Yes, it is fixed sorry I forgot to give an update I’ll be going over this in tommorow’s lesson but reduce_memory is a parameter in TabularPandas now. Install the dev version to use it, else pass in False when working
1 Like
Thanks! I will be joining tomorrow at 4:30AM IST from India
1 Like
Well, everything’s not quite going according to plan. Haven’t been feeling the best the last few days and today we woke up with a fever and almost no voice, so we won’t do a live stream or video (for the time being) for the lecture. That being said, the notebooks will still be at the top, please ask me any and all questions about them here and we can discuss them. I tried to make them more explicit rather than implicit to work around this.
In terms of how to follow the notebooks this week, start with 02_Regression_and_Permutation_Importance, then Bayesian_Optimization, then Ensembling.
General ideas behind each will be summarized below:
-
Permutation importance is an algorithm that can help us understand some of the behavior in our tabular neural networks. While it is not an exact method (as there are many hidden activations and cluster/domino effects from each permutation), it does provide some insight into how a neural network is performing. As a whole it operates by shuffling a column and seeing how the shuffled version’s accuracy (or whatever metric we choose to use) was compared to the original accuracy. Ideally this should be done with either a third seperate test set or the validation set, depending on what we want to interpret (do we want to see how it behaves on unseen data or on training data). We will go more into interpretability in the next lesson with
SHAPand myClassConfusionlibrary -
Bayesian optimization is a form of hyper-parameter tuning that we can do inside the library. Note that the library used in this notebook just allows for continuous parameters (we can get around this somewhat by casting ints)
-
Ensembling: This notebook shows how we can utilize a tabular neural network to further improve other algorithms such as Random Forests or GBM’s, and shows how the
TabularPandasdata can actually be used for any framework! (which is honestly one of my favorite parts)
New bits to the API:
If you notice, now we have two parameters that we are passing into the notebook, inplace and reduce_memory. Both of these are to try to reduce the memory overload in which we are building our data from. inplace will make it so TabularPandas operates out of a single instance of your DataFrame (by default it makes a copy). To use it, set the following from a cell: pd.options.mode.chained_assignment=None. reduce_memory will preprocess your data and convert your categorical data into pandas’ Category datatype, and will convert numbers into float32's. After some experimentation we could reduce the memory usage by up to 50% in some cases. When the dataframe is larger its overall effect seems to diminish, but this is something to play around with
If there are any questions or further clarification needed please feel free to request so
3 Likes
@muellerzr I want to thank you for all the effort you put on this course, I’m watching the lectures since the beginning and it helped me immensely to get familiar with fastai and I learned a lot of new cool and important techniques! (My favorite one being cat points, because I just felt in love with putting cats on hats)
I sincerely don’t know how do you find so much energy to keep up with all of this, truly amazing.
Now please, please take a time to rest and get well, you deserve that.
2 Likes
Ok get well soon @muellerzr! I have just started learning this mega series with starting from Tabular data, it’s so awesome to see your lectures and learning new things!(I decided to postpone following fastai Practical Deep learning course by Jeremy to June).
Thanks for answering all the queries and helping us all out
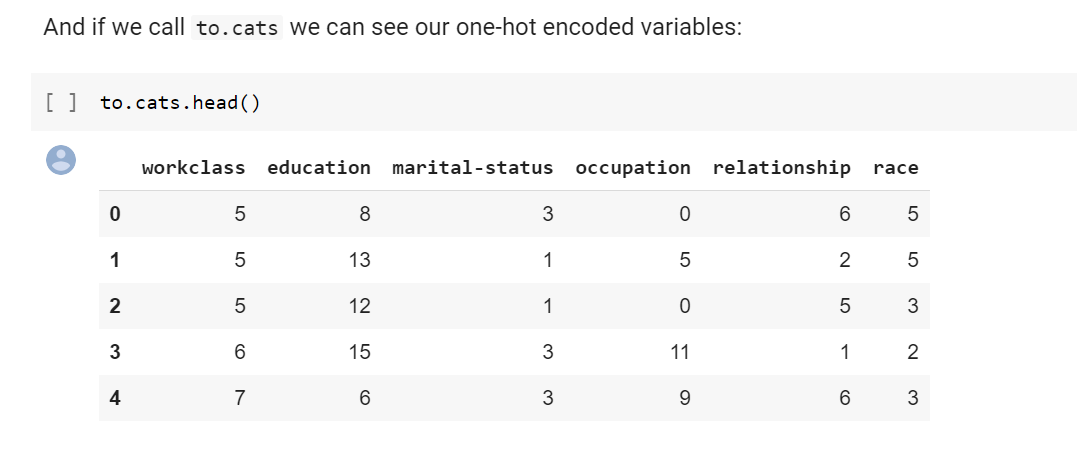
Question - looking at Categorify(), it looks like if variables are not one-hot encoded but just integer encoded. This is usually not correct since it assumes some ordering. What am I missing?
1 Like
Just a partial gap in my thinking. Just had to google Label Encoding vs One Hot Encoding. We’re doing label encoding here ![]() (if someone wants to make a PR with this typo fix feel free to, I’ll try to get to it in the next day or so)
(if someone wants to make a PR with this typo fix feel free to, I’ll try to get to it in the next day or so)
Do you feel though it is correct? I believe we should be doing one hot encoding in this context, since there is no implicit ordering in the columns, i.e. no marital status is “higher” than any other.
Not per-say, but remember these get passed to our embedding layers, and so there could be some relationships between them all. This allows it to be explored (besides that I’m unsure, it’s a design bit done since the old v.07, I’d say experiment and see if it performs better or worse ![]() )
)
1 Like

-
I would say here that ‘age_na’,’ are missing fnlwgt_na’ only "eduaction_na’ appears in the final list
-
Looking at the embeddings a bit later, I do not see where this 2 layers come from:
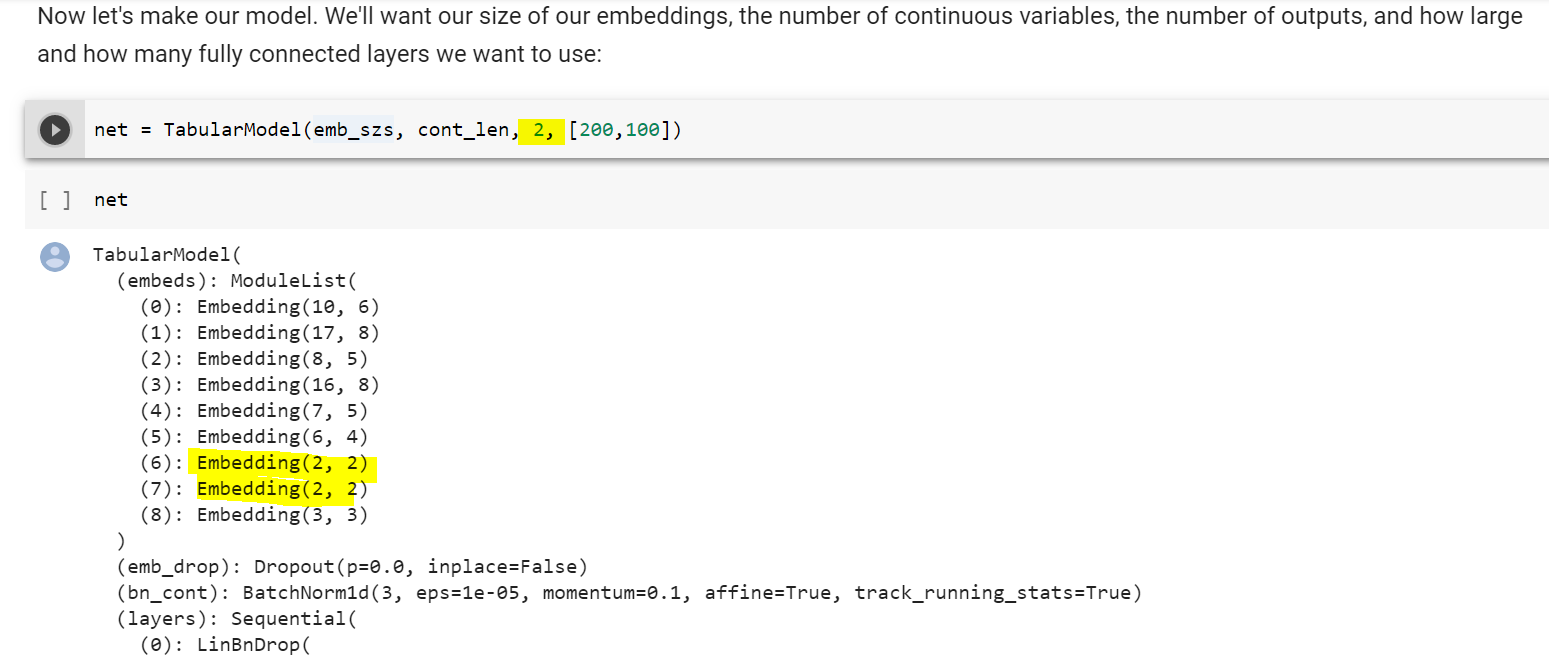
- Moreover, why do we say that the number of outputs is 2? I would have said it is 1 i.e. whereas someone makes more or less than >= 50k.
I’ll look at this in a moment, great observation!
2 possible classes. If we follow tabular learner it’ll wind up calling dls.c for the output (which is 2, and this is further used for the final linear layer’s dimension)
Interestingly enough I don’t get the 2 showing up… let me figure out why and what may have gone wrong…
What does to.train.columns show you?
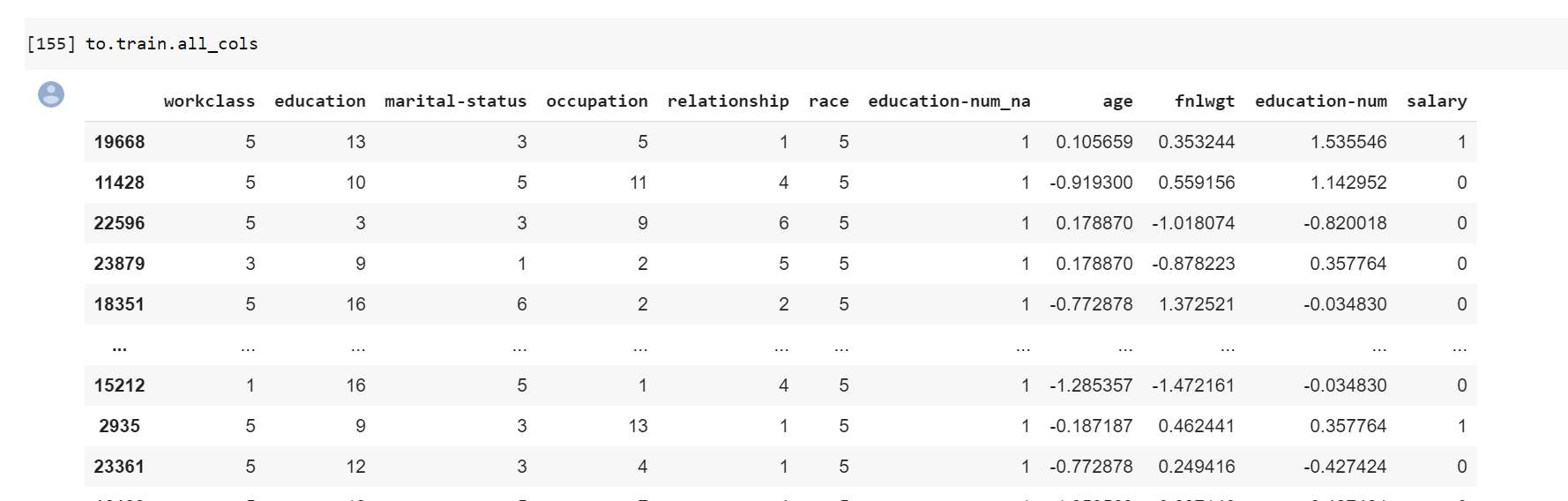
Yes, I find a bit weird that dls.c is 2. I would have said that one output neuron is enough for this problem. 0 would mean <50k and 1 >= 50k.
Also let me know if the last rows are working for you guys. I get here an error:
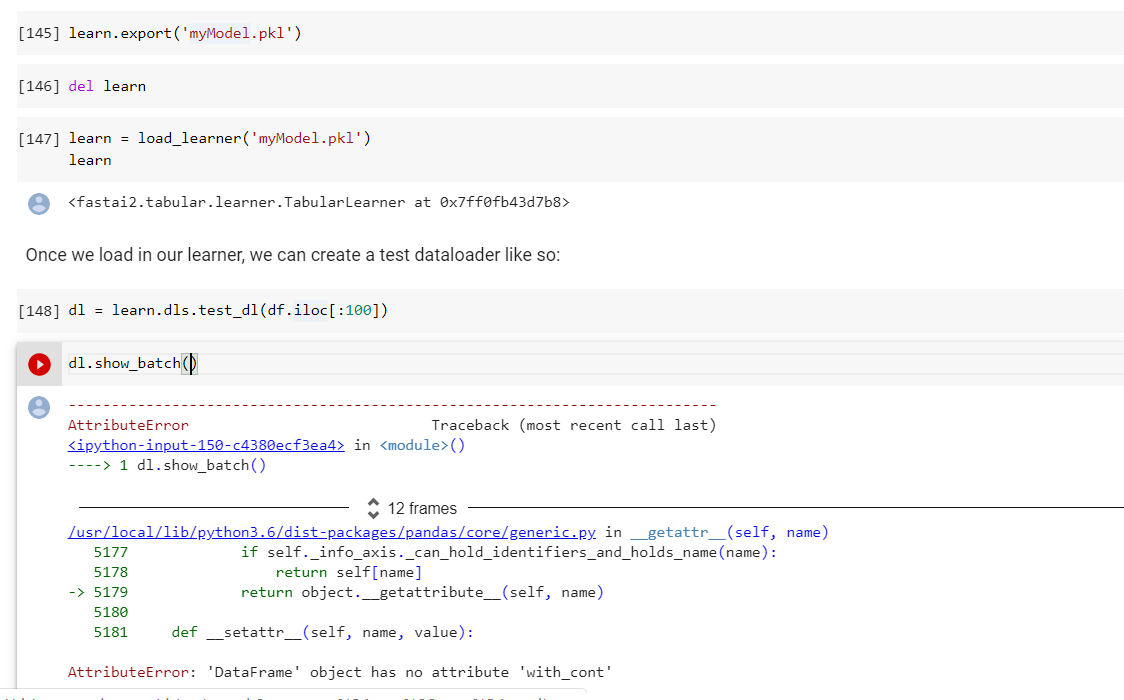
The type of dl is dataframe not dataloader as supposed to, so this is why the cell does not run correctly.
Edit: updated full trace
1 Like
It’s the number of classes specifically, that’s all it is. 0 and 1 is still 2 total ![]()
I’ll look at the last bits. Btw @mgloria try to post the full stack trace for us ![]()
1 Like
@mgloria just ran top down, wasn’t able to reproduce our random (2,2) extras
Here’s what it should look like and I’ll post an updated notebook shortly:
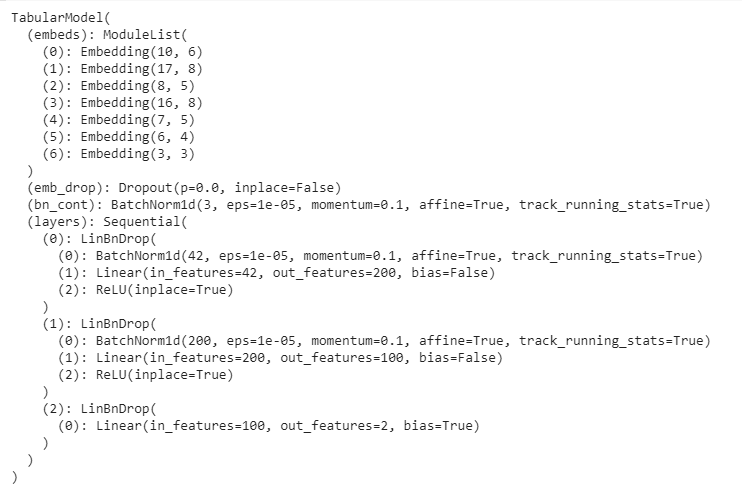
Edit: updated
1 Like
Hi @muellerzr, thank you for this amazing study group. I have a question regarding how to set layers. In notebook 2 the layers were [1000,500] for the learner, is there a way to know how much to set? Thanks!