While we want to develop our dl code with randomization in place, often it helps to be able to reproduce a specific situation, so unless you control the seed you may have to waste hours trying to re-run your code again and again, hoping a similar situation will arise. But why not take control over the seed, so that we still randomize, and yet, know what specific seed to use to reproduce a desired situation. Here is how you do it:
Have this at the top of your nb:
import random, torch, numpy as np
def random_ctl(use_seed=0):
seed = use_seed if use_seed else random.randint(1,1000000)
print(f"Using seed: {seed}")
# python RNG
random.seed(seed)
# pytorch RNGs
torch.manual_seed(seed)
if torch.cuda.is_available(): torch.cuda.manual_seed_all(seed)
if use_seed:
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# numpy RNG
np.random.seed(seed)
return seed
# set to 0 to be in random mode, or to a specific value if you want a specific reproducible case
bad_seed = 0
#bad_seed = 5079
random_ctl(bad_seed)
So normally everything will be randomized. But since the seed is now logged, if at any point you get super bad (or super good) results and you want to study those in depth, just note the logged seed and feed it to random_ctrl.
Logically, you’re making a correct statement, @tyoc213. The issue is that we don’t know what settings the user had originally. While torch.backends.cudnn.deterministic is probably OK to assume we want it to be False during the normal usage, this is not quite the case with torch.backends.cudnn.benchmark which would actually make things slower if your input varies and in some other cases.
The way I use this helper function is restarting the notebook with the seed or without it as needed, so whatever the defaults are it gets them right w/o the explicit seed. i.e. I don’t need to restore the original settings.
For persistence, or if you adopt this function to be used in a different way, to be correct the code should be changed to store the original values somewhere (class or globals) and restore them to those original values if the explicit seed is not used, rather than toggling them.
It works, unless you have some other code that resets/alters the seed elsewhere. I didn’t invent anything new, that’s what everybody else uses, I just put all those multiple statements in one function.
Make sure bad_seed is not 0 when you call this function to reproduce.
Hi Anel. This question has had lots of forum activity over the past years. I think the issue is where the random seeds get invisibly reset. I understand that setting them once at the top of the notebook should work, but I know empirically it is NOT sufficient to get reproducible outcomes.
Here are some places where one of the RNGs is used:
For train/validation split
For data augmentations
To initialize model layers weights
In each worker process that loads data (or use one worker), so before fit().
Honestly, I can’t recall all the places where the reset needs to be done, but I think someone has already found and shown them in one of the many forum posts on this topic.
HTH, Malcolm
P.S. This same question comes up again and again. If you made a demo notebook that definitively demonstrates training reproducibility, it would be a service for everyone.
The problem is not the code, but how it is used. If you rely on the non-linear use of the notebook, this is where the problem happens. NB is handy, but it creates a ton of hidden pitfalls, because you can run the cells at random order.
Summary:
If you run the code from the beginning to the end you and no other component resets the seed to a random value you only need to set the seed once at the beginning of the code.
If you jump back and forth, or, say, re-run just one cell that relies on random order in the functions it calls, you have to re-run the seed setting code every time before you run this cell (or best add it at the beginning of the cell).
thanks for the reply. Actually I am trying to reproduce my own results but no success so far. Of course, as soon as I’ve got something working i will posts it. But to be honest I have absolutely no clue what else to try.
How should we know if our model improves due to the parameter changes we applied or due to randomness? It is really weird that so far there is no reliable solution to this.
Basically run: random_ctl(42) before fit (same cell) or any other cell that you re-run and expect reproducibility.
You need to understand how RNG works. And then you’re golden.
If you have your 10 random numbers lined up 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. (sorted and not quite random for this demo, but I’m just trying to make a point).
and you run a cell that poped the first 5 numbers (0-4), if you re-run the cell again without resetting your random buffer you will end up with the new 5 numbers (5-9).
So every time you re-run the cell that invokes RNG, you have to reset the seed. Hence in that same reply I suggested how one could fix it for any cell (see its p.s.)
IIRC Jeremy even touched on this in the lectures. Having everything be random is an advantage because you can see how the algorithm behaves overall vs having absolute reproducibility can be a hinderance in that regard because you’re stuck there. It should ideally just be used for examples and that’s about it.
Seriously, instead of helping a person to figure out how to code in python in jupyter environment, you tell him don’t bother, because who needs to know how to run reproducible code…
Perhaps I worded that wrong there, my apologies @stas. I don’t deny reproducible code is extremely important, and all your points are exactly right. If we want reproducible results exactly we need to be very careful and precautious about the seeds as there’s many different points in which they are being used. I had simply meant that overall the algorithms (from a fastai perspective) if done right should all behave in the same ballpark or so. But from a teaching and example threshold (or presentation perspective) yes exact reproducibility is needed. Apologies as I know my previous post did not explain that at all (I’ve also used your code many times for that exact purpose for my professors)
Thank you for the clarification regarding RNG.
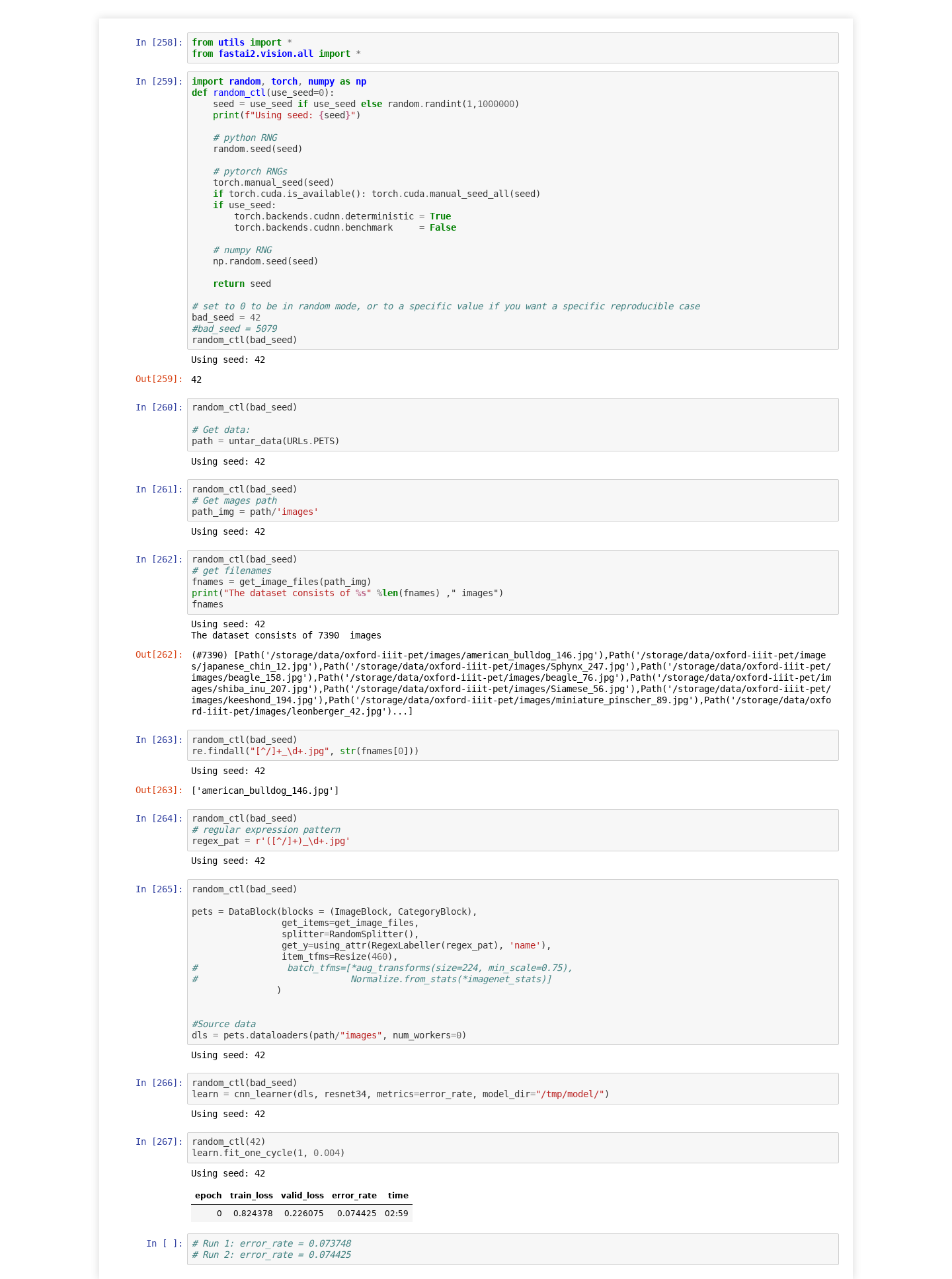
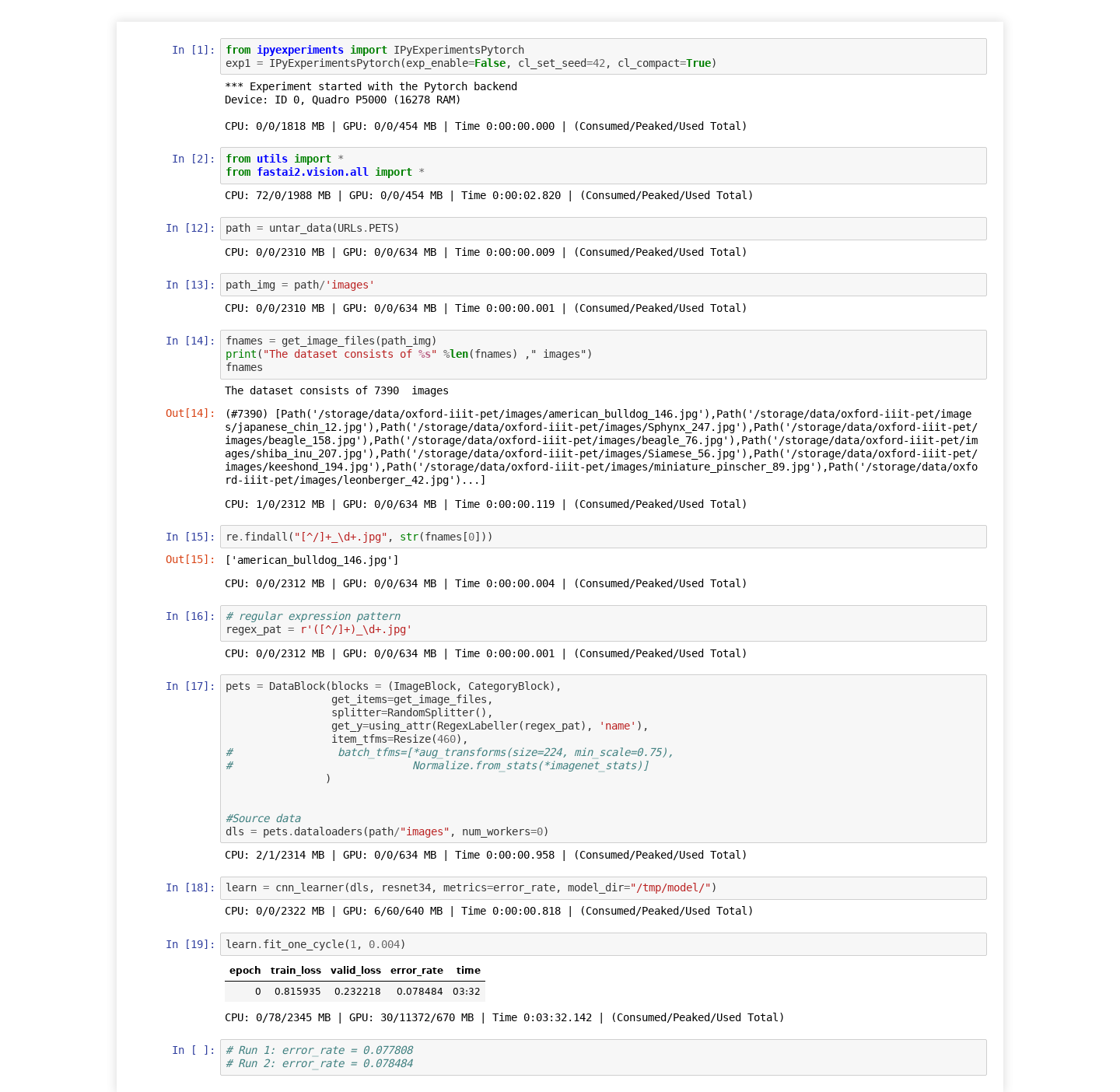
I created a minimal example and completely re-ran the notebook twice from top to bottom.
Each time with different error_rate after fit_one_cycle:
OK, I added an option to reset seed for each cell in ipyexperiments, so you can re-run any cell and the magic will happen behind the scenes. It needs more testing and docs, but you can try:
Looks correct to me. I haven’t tried fastai2 yet, so I won’t know, perhaps there is a bug and it sets a seed in the fastai code disregarding user settings? Especially, since the fastai philosophy is to randomize on purpose.
Do you see the same behavior with fastai v1? If I remember correctly it used to give reproducible results if you manually set the seed.
You can file a bug report, I’m sure Sylvain will sort it out in no time.
By now I am sure that you are right and that fastai2 is the cause.
I will try to repeat the same using fastai1 and provide my results here for future strugglers.
yes, of course, my module just saved you retyping the seed reset in each cell. if it doesn’t work in the first place when you did it manually, then you won’t see a different behavior. I thought that your original problem was that you were re-running the same cell with different parameters and were expecting the same random sequence. But based on your example this is not the case, so it’s not the wrong usage, but a fastai2 library issue.
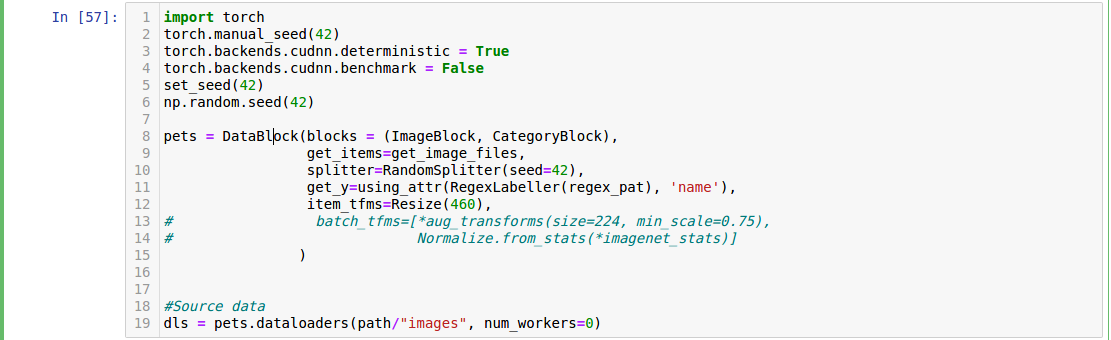
Most likely fastai2 somewhere sets the seed, it needs to be found and made configurable with the default not to set it and thus allowing user to control the behavior.
 (I’ve also used your code many times for that exact purpose for my professors)
(I’ve also used your code many times for that exact purpose for my professors)