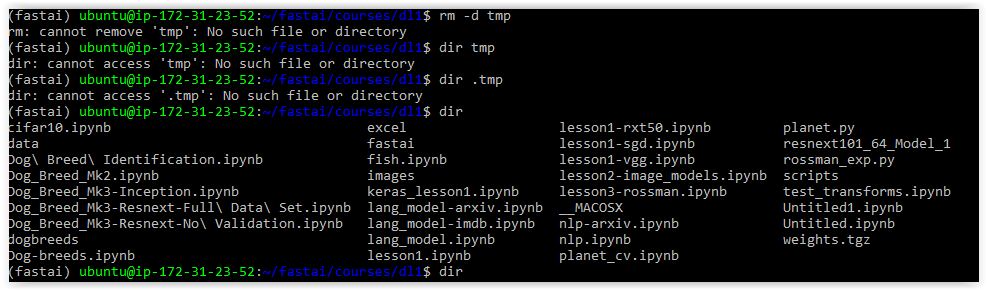
Still getting the error!
Here is my entire script (just the actual setup parts):
from fastai.conv_learner import *
PATH = "data/dogbreed/"
arch=resnext101_64
sz=224
bs=64
label_csv = f'{PATH}labels.csv'
n = len(list(open(label_csv)))-1
#val_idxs = get_cv_idxs(n, val_pct=1e-4)
#val_idxs = get_cv_idxs(n, val_pct=0.01)
val_idxs = [0]
n, len(val_idxs), val_idxs
# (10222, 1, [0])
label_df = pd.read_csv(label_csv)
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
data = ImageClassifierData.from_csv(PATH, 'train', f'{PATH}labels.csv', bs=bs, tfms=tfms,
val_idxs=val_idxs, suffix = '.jpg', test_name = 'test',
num_workers=4)
fn = PATH+data.val_ds.fnames[0]; fn
# 'data/dogbreed/train/000bec180eb18c7604dcecc8fe0dba07.jpg'
## why is it going to my train directory maybe I need to redistribute images
# to suit reconfiguration of data sets??
# to be sure check just one image in val set, an error is generated if I attempt to
# reference another image
data.val_ds.fnames[1]
# ---------------------------------------------------------------------------
# IndexError Traceback (most recent call last)
# <ipython-input-12-be174aefb09c> in <module>()
# ----> 1 data.val_ds.fnames[1]
# IndexError: index 1 is out of bounds for axis 0 with size 1
fn = PATH+data.test_ds.fnames[0]; fn
'data/dogbreed/test/fd1a7be32f10493735555e62913c0841.jpg'
fn = PATH+data.trn_ds.fnames[0]; fn
# 'data/dogbreed/train/001513dfcb2ffafc82cccf4d8bbaba97.jpg'
def get_data(sz, bs):
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
data = ImageClassifierData.from_csv(PATH, 'train', f'{PATH}labels.csv', test_name='test',
val_idxs=val_idxs, suffix='.jpg', tfms=tfms, bs=bs)
return data if sz>300 else data.resize(340, 'tmp')
sz, bs
# (224, 64)
data = get_data(sz, bs)
learn = ConvLearner.pretrained(arch, data, precompute=True, ps=0.5)
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-47-0708a7145fb8> in <module>()
----> 1 learn = ConvLearner.pretrained(arch, data, precompute=True, ps=0.5)
~/fastai/courses/dl1/fastai/conv_learner.py in pretrained(cls, f, data, ps, xtra_fc, xtra_cut, **kwargs)
92 def pretrained(cls, f, data, ps=None, xtra_fc=None, xtra_cut=0, **kwargs):
93 models = ConvnetBuilder(f, data.c, data.is_multi, data.is_reg, ps=ps, xtra_fc=xtra_fc, xtra_cut=xtra_cut)
---> 94 return cls(data, models, **kwargs)
95
96 @property
~/fastai/courses/dl1/fastai/conv_learner.py in __init__(self, data, models, precompute, **kwargs)
85 elif self.metrics is None:
86 self.metrics = [accuracy_multi] if self.data.is_multi else [accuracy]
---> 87 if precompute: self.save_fc1()
88 self.freeze()
89 self.precompute = precompute
~/fastai/courses/dl1/fastai/conv_learner.py in save_fc1(self)
132 self.fc_data = ImageClassifierData.from_arrays(self.data.path,
133 (act, self.data.trn_y), (val_act, self.data.val_y), self.data.bs, classes=self.data.classes,
--> 134 test = test_act if self.data.test_dl else None, num_workers=8)
135
136 def freeze(self):
~/fastai/courses/dl1/fastai/dataset.py in from_arrays(cls, path, trn, val, bs, tfms, classes, num_workers, test)
296 ImageClassifierData
297 """
--> 298 datasets = cls.get_ds(ArraysIndexDataset, trn, val, tfms, test=test)
299 return cls(path, datasets, bs, num_workers, classes=classes)
300
~/fastai/courses/dl1/fastai/dataset.py in get_ds(fn, trn, val, tfms, test, **kwargs)
264 def get_ds(fn, trn, val, tfms, test=None, **kwargs):
265 res = [
--> 266 fn(trn[0], trn[1], tfms[0], **kwargs), # train
267 fn(val[0], val[1], tfms[1], **kwargs), # val
268 fn(trn[0], trn[1], tfms[1], **kwargs), # fix
~/fastai/courses/dl1/fastai/dataset.py in __init__(self, x, y, transform)
160 def __init__(self, x, y, transform):
161 self.x,self.y=x,y
--> 162 assert(len(x)==len(y))
163 super().__init__(transform)
164 def get_x(self, i): return self.x[i]
AssertionError: