You should use the same existing model that you already trained and retrain it with the entire set following the exact same steps you took. If you switch to a different model then you would want to start from the beginning with tuning train/ validation set.
@sermakarevich I see you are celebrating your new top score on dog breed with a fancy new profile picture LOL 
4 Likes
Can you please share you notebook then? With ls of main folders?
@jamesrequa hehe ) Previous one was a hand X-ray from @yinterian notebook but its invisible when small.
Thanks - it would be great if Jeremy could document this process - maybe someone else has!
BTW I have recently tried this with Inception Resnet V2 (previously was using Resnex 101 64) and I am getting better results, but I have had to adjust the learning to give it more cycles, and even with that approach my training error exceeds my testing error. Do you have a strategy to move this architecture from underfitting towards a better balance?
Wow, using resnext101 and some of these techniques I made it into the top 50 on my first try.
fast.ai for the win 

4 Likes
A month ago this would be 1-st place score!
2 Likes
Here’s where I’m at now: deeplearningstudy/FADL1/dogbreeds.ipynb at master · WNoxchi/deeplearningstudy · GitHub
I’m following along with the lesson 2 notebook: https://github.com/fastai/fastai/blob/master/courses/dl1/lesson2-image_models.ipynb
With ls of main folders?
Note sure what you mean by that. Dir structure I’m using is:
data/dogbreeds/
data/dogbreeds/labels.csv
data/dogbreeds/train/< jpg-files >
data/dogbreeds/test/< jpg-files >
Edit: looks like from_csv(..) is expecting data folders to be in a train.csv/ folder? Odd since the dl’d them from Kaggle as zipped jpegs. I tried changing the name of the train/ folder to train.csv/ but no change.
You can specify a folder name with images. Now you ask from_csv to look for images in train.csv/ folder. Do you really have this folder and all train images in it?
Yeah. Renamed the folder back to train/, I thought data/trn_dl/dataset/fnames was defaulting to a train.csv/ path for images, but that’s not the case: back to train/< img-name > after I renamed & restarted.
So it’s able to find the images… It can see the labels… don’t know yet why it doesn’t seem to be working. Training generally yields horrendous losses as well, so something’s not right.
Try deleting data/dogbreeds/tmp folder and redo all steps once again.
No difference. I tried upping the batch size to 32.
The plot is starting to have the right shape, but the numbers tell a different story: that drop is a difference between 5.6 and 5.2 …
I can’t know without seeing their work, but I doubt the people here getting high rankings are seeing numbers that bad.
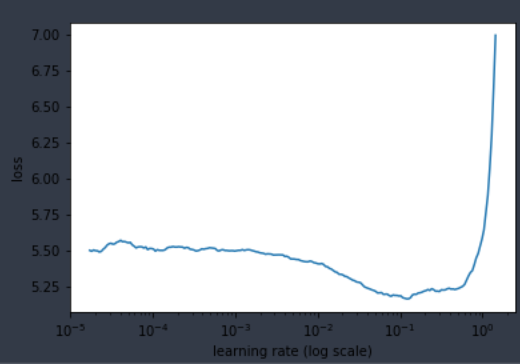
Edit: Hmm… I had a hunch… looks like batch-size is playing a big role. Here bs is upped to 64; lowest loss around ~4.4
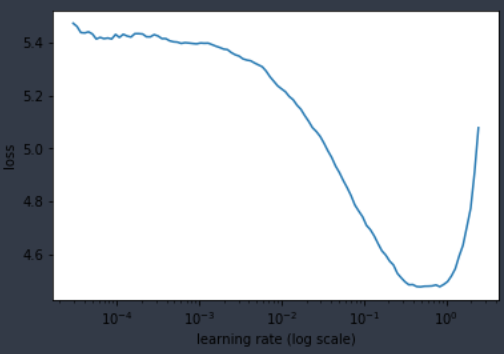
Does this seem right? Shape & Loss-Numbers wise?
n = len(list(open(label_csv)))-1
val_idxs = get_cv_idxs(n)
Is not this mean you have all your images in validation and nothing left for train ?
updt: no, it takes 20% of n
Shape looks good. Can’t say anything about loss until you actually train a few epochs! ![]()
You might also want to consider adding a reference to your folder with test images: test_name='test' , otherwise you’ll get stuck later, if you want to create a Kaggle submission, and you would try to run this: learn.TTA(is_test=True)
…been there, done that
data = ImageClassifierData.from_csv(path=PATH, folder='train', csv_fname=label_csv,
bs=bs, tfms=tfms, val_idxs=val_idxs, suffix='.jpg',
test-name='test')
1 Like
If I got it right, there’s a default validation-percent parameter, val_pct in get_cv_idxs(.) that’s set to 0.2 – so I’m using the default 20% validation set size.
@jeremy got it; I’m trying to make sure I’m pointed in the right general direction before I start charging into oblivion 
So far I’m down to a trn/val loss of 2.547…/2.434 after 4 epochs at lrs=1e-1 … so… seems like the right direction. We’ll see.
@Antti yup, discovered that last week I think there’s a set_data method letting you add it in later on which is very useful.
One note: is learn.data.sz returning batch size instead of image sizes? I just noticed it’s giving me my batch (64) size even after I resized to 300.
Is it possible you are passing the batch size instead of image size, something like this:
tfms = tfms_from_model(arch, bs, aug_tfms=transforms_side_on, max_zoom=1.1)
instead of
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
Hi @jamesrequa
Regarding this, after training with validation, is the correct process as follows :
set val_idxs = [0]
data = get_data(sz_bs)
# I am currently in precompute = False, as that was the state of my model after training with validation
# Do I need to repeat all steps, including my "warm up" with precompute=True ????
learn.precompute = True
learn.fit( ... my parameters with precompute=False ... )
learn.precompute = False
learn.fit( ... my parameters with precompute=True ... )
log_preds, y=lear.TTA(test=True)
etc...
@Chris_Palmer Everything looks good except…I think you can skip precompute = True so just follow all of the same steps you did before starting with precompute = False and follow those same parameters throughout.
Just to clarify a bit more why you should skip precompute=True is because your activations were previously generated based on your validation set and training set split. So if you set that to True with now a different training set (contains validation images) and validation set (only has 1 image) now you basically have to generate all the activations over again anyway and the ones you had saved previously couldn’t be re-used in this case.
Also just a reminder to convert your logs into probabilities
preds = np.exp(log_preds)
Thanks James
And getting these into a format to submit to Kaggle - how is that done? I guess there is a lot of information available about it - I think Jeremy has recently posted something - but it is a step after running the preds = n.exp(log_preds) ?
Yep I think this process has been covered a few times in this thread and other threads in the forum but here are links to two of my posts with some references that should help you out! In particular the one from Jeremy posted to the top of Lesson 3 Wiki is a line by line code example on submitting to kaggle for dog breed comp.