As you can tell from my other post, I am trying to find ways to (lawfully) increase my training data. The idea of using all of the data was recommended by @jeremy but I still have not found a way to work out how to do that!
Another thing that puzzles me (if I understand it correctly) is that our augmented data is only used in testing via the .TTA method. I thought that we should have the augmented data available to increase the size of our training set!
Just to clarify, you are just trying to use all of your data as train and none as validation? if so, just set val_idxs=[0] This isn’t exactly what you want, but it is the easiest way to do things currently. It puts one image into the validation set and the rest into training. You won’t get very much feedback at this point though so it’s important that you already have your model all set up how you want it before making this change.
To create the valid set, I randomly picked 1/5th of the images of each breed and put them into valid/breed_name folder. Test set is as it was when unzipped from files downloaded from Kaggle.
It will use the augmented data in training only if precompute is set to false when generating the model. If precompute is set to True then things get a little murkier for me. I think at that point, the model is loaded with the activations and won’t change. I would love to hear somebody else answer that better than me though because I am still trying to work through precompute = True vs precompute = False and freeze() and unfreeze()
Augmentation is definitely a way to increase the size of your training set. It takes the picture and looks at it with different rotation, zooming, coloring, etc which can help make a model that is more generic and can help predict the test data better. Maybe there is an image of the same dog breed, but the camera is slightly closer or farther away. This lets you simulate that image possibility.
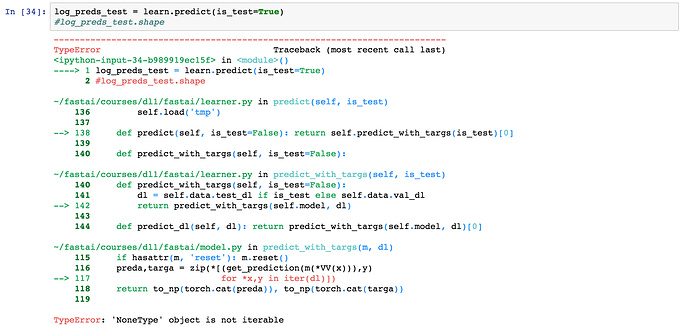
Yep, looks like that is your problem. You are telling TTA predict that you want to use test, but you haven’t said where that is exactly. If you do Shift + Tab when you are in the from_paths command, you will see the arguments it can take and what the defaults are. Train and Valid both have a default value, but test doesn’t so you have to do something like this (your other stuff looks fine, this is just from mine):
Alright, I can’t figure out at all how to create a csv file to submit to kaggle. I can’t find anything in the lecture 2 video either, so could someone help me with getting the code for that? Thanks!
I think you have answered my question re augmentation - it DOES use augmented images when you set precompute=False. Is this necessary because if using precompute=True then the model can ony deal with images it has previously seen? If this is the case, then what purpose would there be in doing any warm-up training when precompute=True?
Which competition are you referring to? I assume since you are posting to this thread then its for Dog Breed? The code can vary quite a bit depending on which one it is
Generally speaking I always start by using the submission_file.csv that kaggle provides for each competition as my df with a simple line like submission = pd.read_csv('sample_submission.csv'). From there you just replace the ids in the sub with your test ids (so they are sorted correctly/aligned with predictions) which you can grab from here data.test_dl.dataset.fnames. Then you fill in the rest of the columns in the df with your predictions.
Check out this link. This really helped me get a submission generated. Don’t worry so much about the fact that it is for vgg19. Focus on the exporting to CSV steps near the bottom.

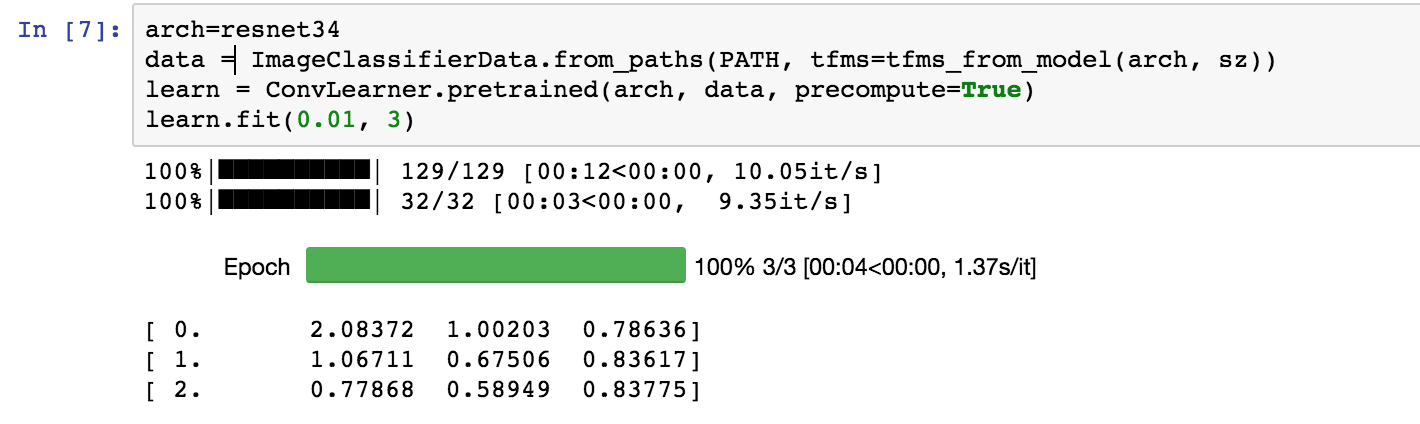
 This was very helpful!
This was very helpful!{kind=link}