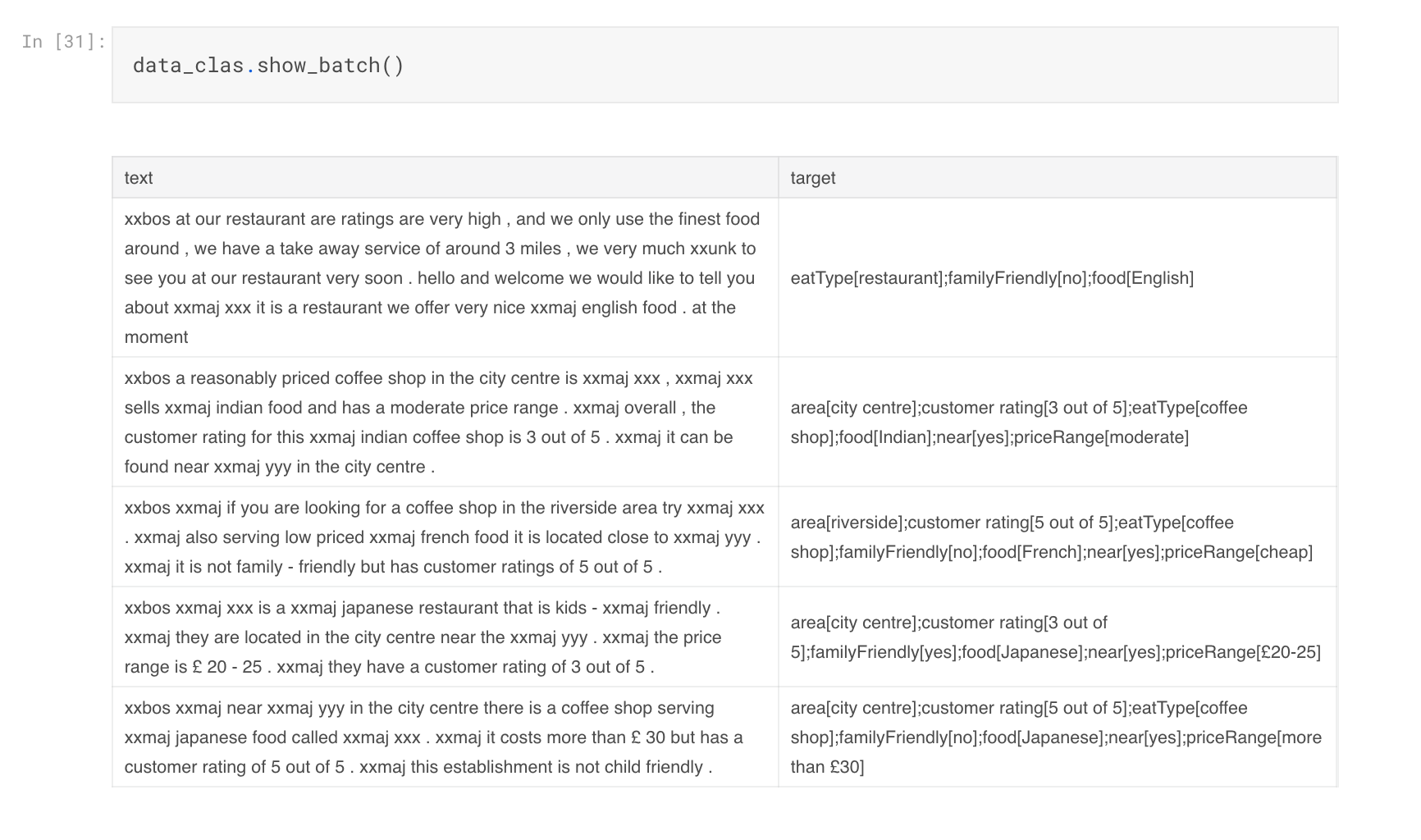
I created a TextLMDataBunch object from a dataframe, as you can see in the picture. Why aren’t all beginning of sentences marked as “xxbos maj”? For example in the output of show_batch, we have “xxmaj yyy in the xxmaj riverside area”. It seems to me that xxbos is used to indicate the beginning of the text in “ref” cell of df, not the beginning of every sentence of every text. Same happens when I create a TextClasDataBunch. How can I change that?

I assumed that xxbos marks beginning of sentence, but it seems to mark beginning of text and it does so for both the language model data (my example before) and the input to the classifier (attached image). I presume the reason for indicating beginning of text is to account for linguistic phenomena like pronominalization.
The actual beginning of sentence is identified by “. xxmaj”.
I see you can turn off that tag in include_bos with TextDataBunch.from_df.
I guess I answered by own question really:-)
Generally, BOS indicates the “Beginning Of Sentence” and EOS for the “End Of Sentence”.
But I found the docs says what these special tokens mean:
UNK(xxunk) is for an unknown word (one that isn’t present in the current vocabulary)BOS(xxbos) represents the beginning of a text in your datasetFLD(xxfld) is used if you setmark_fields=Truein yourTokenizeProcessorto separate the different fields of texts (if your texts are loaded from several columns in a dataframe)TK_MAJ(xxmaj) is used to indicate the next word begins with a capital in the original textTK_UP(xxup) is used to indicate the next word is written in all caps in the original textTK_REP(xxrep) is used to indicate the next character is repeated n times in the original text (usage xxrep n {char})TK_WREP(xxwrep) is used to indicate the next word is repeated n times in the original text (usage xxwrep n {word})
Yes, hence my surprise at the outputs of show_batch where BOS does not seem to indicate beginning of sentence. Or should the input be formatted on sentence per row in the dataframe? Am I missing something?
@thousfeet, my bad, this is a case of RTFI (the docs that you kindly pasted), but for my defence BOS in NLP normally means Beginning Of Sentence, whereas here it means Beginning Of Stream (as explained at 1:44:17 of Lesson 7).
2 Likes
It marks a boundary between items in your data so that the model can learn that it should start a new sequence rather than continuing the previous sequence.
Items get smushed together when training a language model so letting the model know where one item ends and another begins is important.
How can we remove these tags in Fast AI v2?