Hi there, how are you doing?
I just finished Lesson 4 MNIST and I’m going through it again doing things a bit differently. Instead of using MNIST_Sample, I used MNIST. I noticed that there are only training data in this set. So I decided to split those data into training and valid set.
However, I found out that my dataset is wrong as the result I got (using the optimized Learner module) has starting accuracy of 100% and then degraded.
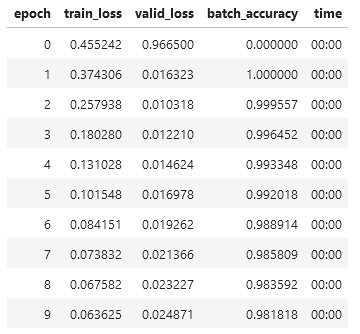
I hope you could take a look of my code and help me debug this problem.
Eight_path = (path/‘training/8’).ls().sorted()
Five_path = (path/‘training/5’).ls().sorted()
Eight_list = [tensor(Image.open(i)) for i in Eight_path]
Five_list = [tensor(Image.open(i)) for i in Five_path]
Eight_tensor = torch.stack(Eight_list).float()/255
Five_tensor = torch.stack(Five_list).float()/255
Eight_tensor = Eight_tensor.view(-1,2828)
Five_tensor = Five_tensor.view(-1,2828)
Eight_label = tensor([1]*len(Eight_tensor))
Five_label = tensor([0]*len(Five_tensor))
Data = torch.cat([Eight_tensor,Five_tensor])
Data_label = torch.cat([Eight_label, Five_label]).unsqueeze(1)
def Data_split(Dataset, ratio):
Test_length = round(len(Dataset)*0.8)
Train_length = len(Dataset) - Test_length
return Dataset[0:Test_length-1], Dataset[Test_length-1:]
SplitRatio = 0.8
Data_train, Data_valid = Data_split(Data, 0.8)
Label_train, Label_valid = Data_split(Data_label,0.8)
Train_dset = list(zip(Data_train, Label_train))
Valid_dset = list(zip(Data_valid, Label_valid))
Train_MiniBatch = DataLoader(Train_dset, batch_size = 256)
Valid_MiniBatch = DataLoader(Valid_dset, batch_size = 256)
dls = DataLoaders(Train_MiniBatch, Valid_MiniBatch)
learn = Learner(dls, nn.Linear(28*28,1), opt_func=SGD,
loss_func = loss_fx, metrics = batch_accuracy)