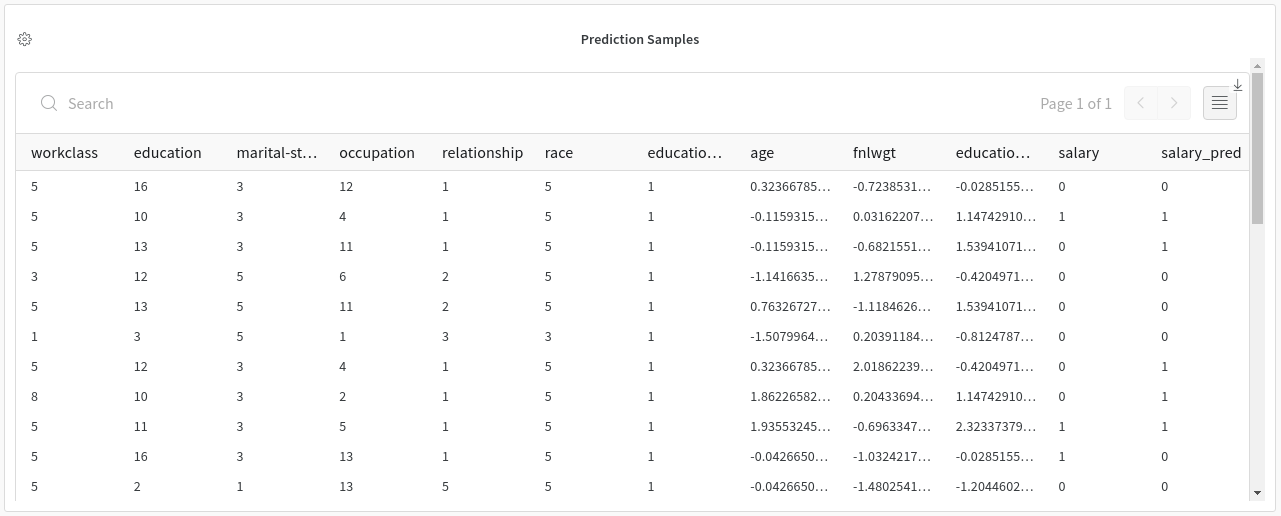
I guess the main issue is that it didn’t show prediction samples (loss should still be logged as well as hyper-parameters).
I’m currently working on supporting bounding boxes and can take a look at tabular right after. I definitely want to support most of common types.
We can actually log tables so it’s just a matter of preparing correctly the DataLoader, getting prediction samples and decide what we want to log and how to present it.
Wandb seems like a great tool! I’ve been testing it with a few simple examples, such as the demo notebook mentioned above. I’m able to track the hyperparameters (lr, loss etc), but I can’t seem to track the parameters nor the gradients. I’ve been testing various options to the log parameter in the callback, but no results so far. Any ideas of what I’m doing wrong?
D’oh! There is a default minimum of 100 batches to be run before parameters and gradients are stored: wandb.watch??. Datasets such as MNIST tiny has fewer batches (with normal batch sizes at least).
It is because WandbCallback._wandb_watch_called == True as watch can be called only once per run and once per model.
Technically it could be reset to False when doing a new wandb.init. If it becomes a common issue we could monkey patch it.
You can set it manually to False for now. Let me know if that works.
The issue is related to creating a DataLoader for sample predictions:
we choose 36 items from the validation set → seems to work fine
issue happens at this line when trying to create a DataLoader from those items
I think the problem is that the items fed to TabularDataLoaders.test_dl is a list of pandas.core.series.Series while it should probably be a Dataframe.
When I convert it to a Dataframe with test_items = pd.DataFrame(test_items) prior to feeding it to test_dl, I get an error while fetching prediction samples: see stack trace.
Not sure where the problem is…
I created an experimental notebook if anyone wants to try to tackle this issue.
Resetting WandbCallback._wandb_watch_called = False worked just fine!
But I’m thinking that maybe this is kind of a stupid way of organizing experiments? Previously I’ve often used the notebook itself to “store” experiments - say, testing a few different lrs in sequential cells, but this quickly becomes a mess. So I guess it’s much cleaner to keep the notebook concise, and rather store the results after running the notebook several times over? And if you want to systematically test various parameters, just go for a parameter sweep. Curious to hear other thoughts on workflow!
Wandb sweeps are great, but still, I find a little bit of friction from passing from a single experiment in a notebook to defining a training function for the wandb agent. Maybe calling the notebook itself as a function with papermill and put that into the sweep could do the trick, but I haven’t tried that out yet
I don’t think there is any stupid way. Whatever works well for you is good and you’ll probably change how you do it several times!
I personally like to keep my notebook as short and concise as possible. Whenever you change any parameter (learning rate, batch size, new callback…), it should automatically be tracked with this integration so you can easily see the difference between your experiments in your project run page.
I’ve not looked into it too much but we could patch Learner to do sweeps. The only issue is that it would probably be on a limited number of parameters (batch size, learning rate, epochs…) and it may be hard to make it as flexible as the traditional sweeps. It may be sufficient based on how people use it though. Let me know your feedback
It is a great question. W&B includes the tensorboard dashboard (when used for logging) and additional features.
My favorite feature is its ability to centralize experiments and quickly compare them.
When I have a complex project, I typically try a few different ideas and pull my comparisons into W&B reports to write my reasoning along the way. Helps me think more clearly.
They have a comparison section in their documentation but I would recommend you just to do a test on a few runs as it will be easier to understand.
These are saved as string so if you play a lot with these, it may not be completely straightforward to organize your runs. As an alternative we could also extract each value such as dls.after_batch.IntToFloatTensor.div (float) but it may not completely help (Normalize.mean is tuple of 3 floats here). I’m thinking of letting this explicit description as is for now.
@boris thank you so much for all your work. This callback is really cool and a delight to use.
I think even a limited use of the sweeps functionality as a patch to Learner would be 100% worth it. I personally wouldn’t write a custom script (yet) to use sweeps, so trying it out without additional effort is a huge win for users like me.
I think it makes sense for the log_model and log_dataset functions to expose description as a parameter rather than fixing it to 'trained_model' and 'raw dataset' respectively.