You can add a folder (e.g., custom) within fastai module directory. Your directory might look something like -
fastai/
– tabular
– utils
– …
– custom
You may add user defined modules under custom folder. git pull won’t overwrite/revert your changes. If you want to have git tracking for custom files as well, you may want to fork the fastai repo and push your custom code to the fork.
In your code, you would import the function as - from fastai.custom import function_name
You can add the module to existing folder as well, but to keep user code separated from upstream it might be easier to have it under a different folder.
Hi,
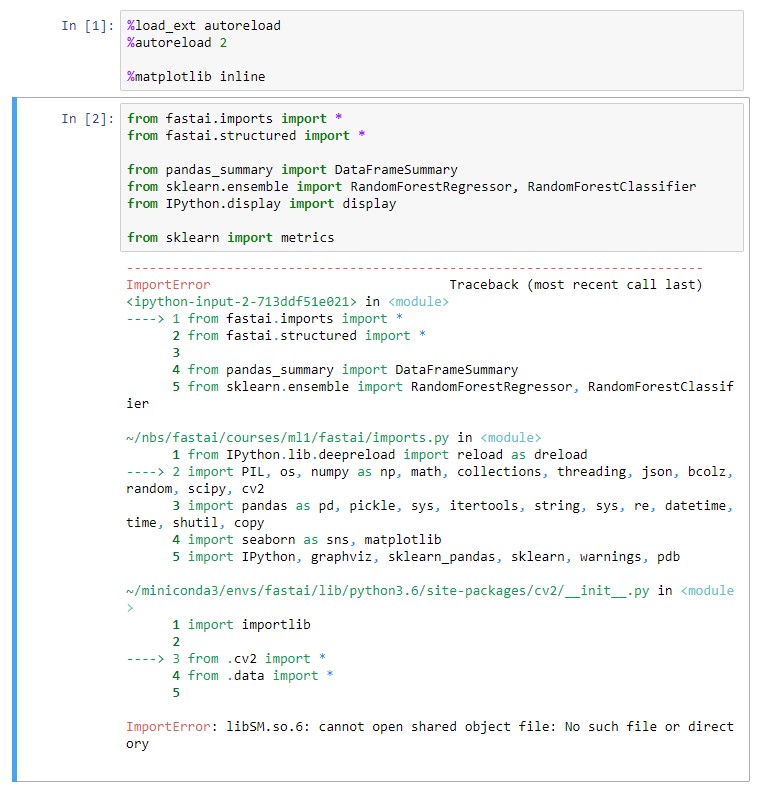
I am a bit stuck after setting up fastai on ubuntu (windows subsystem for linux).
I tried to run the code from the jupyter notebook lesson-rf1, but it gets stuck at the second cell. It throws this error:
I have deployed the DSVM image (Linux version) in Azure and I’m able to connect to the machine via a SSH session. However when I browse to the machine remotely and succesfull login I receive an error message:
500 : Internal Server Error.
On the 3rd video / lesson he explains that you will use the dictionary values stored on nas to “process” the Test Set in the same way you did to the Training Set, in order to produce the predictions that you want to submit.
train_set= f ( train_csv )
the nas is somehow similar (not equal) to that f(x)
so then you do
val_set= f ( val_csv )
To add on to what @jacksonisaac mentioned, we have to fill the missing value with something. And by filling it with the median we preserve the overall median of the data, with likely a minimal impact on mean and standard deviation. Filling with other values will have a different impact on the distribution of data.
type(test_df) # o/p: pandas.core.frame.DataFrame
# test_df is a DataFrame numeric values along with missing values
test_df = proc_df(test_df)
# test_df is now a list
type(test_df) # o/p: list
test_df is getting converted to list. I have no idea why.
Any help? Thanks
hello everyone can some please help, i am currently doing the intro to machine learning course, part 2 specifically, and i decided to take a leap of faith and analysed a random data set, and i got these scores, but because i’ve never seen them it’s really hard to say what they mean, i am use to less scores, eg 0.025
but this:
a) rmse of training set, b) rmse of validation, c) score of train, d) score of valid
[2.6473913845249957, 5.991807398439978, 0.9940291743929885, 0.8914779738266136]
i’ve tried everything, none is working,
if you want i can upload everything to github, for better analysis.
In the course video, @jeremy said something about Machine Learning Driven EDA. I’ve finished lesson 4 and I still don’t really get that what means. Will he talk about it later in the course?
Hello! I try to find ml1 but there is not. I use google cloud and I follow this path tutorials/fastai/course-v3//nbs/dl1. There is no option ml1! Nore somewhere in tutorials!
I updated the course repo. Did anybody have the same problem or has an idea how could I fix it?
Thanks!
I’m following the lesson with FloydHub, which the best option I found until now, but I’ve noticed that the GPU utilization is stuck on 0 while running the random forest.
I checked if the CUDA driver is being being recognized and it is. I tried to play with it but with no success, anyone has an idea why might the fastai library not utilize the GPU? (CPU is at 100%)
Hi,
I hope you found what you were looking for by now (6 weeks later), and you dont need this answer.
But just in case you do: clone the fastai/fastai repo, you can find ml1 in the courses folder.
Here is a link: ML1 folder
Hope this helps if needed, but I hope even more than you had already solved your pb.
Cheers,
Lamine
Hello every one. I see that we don’t have a clear tutorial on how to connect to AWS and open a Jupyter notebook from Windows, so I want to share how I did it here. Maybe this topic is too basic for a lot of people but for a complete beginner like me it took me several hours to figure it out, especially when I didn’t even know what an SSH tunnel is. So I think it will help a lot of beginners to quickly get through this step and get to experimenting with the lecture.
Hi @sturkian The easiest option in my opinion is to use Google Colab. Here’s a Jupyter notebook to guide you through the steps needed to properly run the course notebooks in Google Colab: Colab setup for Part 2 2019