Hi All. I had a play using fast.ai v1 instead and seem to be able to get everything to work. The short of it is that a bunch of functions from structured.py need to be copy + pasted over, and the feather loading is slightly different. Nothing else major had to change that I came across.
I am not sure why these functions were completely thrown away from the repo, but there is a new tabular section for NN which might be worth taking a look at. It would be interesting to hear from @jeremy what his plan is for this course and in particular if things are in for a shake up now v1 is out?
Thanks for doing this! I would love to see a fastai v1 compatible version of all the course. If there are important missing bits of missing functionality, I’d be happy to discuss ways to make them work. I’d like to find a more integrated way of doing things overall - fastai v1 is much more carefully designed than 0.7, so hopefully we can find neat ways of incorporating all the functionality required.
(This will require a community effort however - it’s not something I have time to do myself at the moment.)
I was secretly hoping you would have run a course this year with v1 or will be soon, and would update accordingly As mentioned, there is just a handful of helper functions required (at least for the random forest portion of the course), so I think it would not be hard to keep it working / alive.
Integrating it with the new structure (which looks quite impressive!) I can’t comment on, but I’m hoping to play with the new features in the coming weeks. I have found the random forest portion of the course fascinating though (such a good insight despite already having been exposed to them previously) and it would be great to keep the simple functionality of them alive.
Can someone please help me to download the data for lesson 1 of machine learning?
in kaggle its asking for my phone number and I am from INDIA, so sms(pin) cant be reached
pls help
I would like to know how one can add its own functions to the fastai library to make it available to all notebooks.
For example, I have written the following small function to convert every datetime column into categories:
columns = list(df_raw)
n_columns = len(columns)
for n in range(n_columns):
if df_raw[columns[n]].dtype == '<M8[ns]':
add_datepart(df_raw, columns[n])
I’d like to save it somewhere so I can use it in future notebooks. I guess I can just write a python file, but I don’t know where to save it. Also, I’m afraid that it will be overwritten whenever I git pull. Does anyone have any advice to give me on this?
I’d like to know how to better approach categories order after running the function train_cats(). In lesson 1, Jeremy rearranges the order of the category ‘UsageBand’.
Do we have to look at each category created and update their order if it is wrong? It seems like a slow process to do this for each category column.
Just one little tweak from @mrbruce’s work was I had to change is_string_dtype to pd.api.types.is_string_dtype
Also, I might be doing something wrong, as I’m getting pretty different results in some spots from others were getting. I’m going to go through the lesson again with this working and see what’s what.
In the notebook the SalePrice is converted to log of that SalePrice. But doing that makes our predicted values also have log(SalePrice). So when we submit this output to kaggle we will be getting very bad result. So actually it is better to compute the log in the definition of RMSE.
HI,
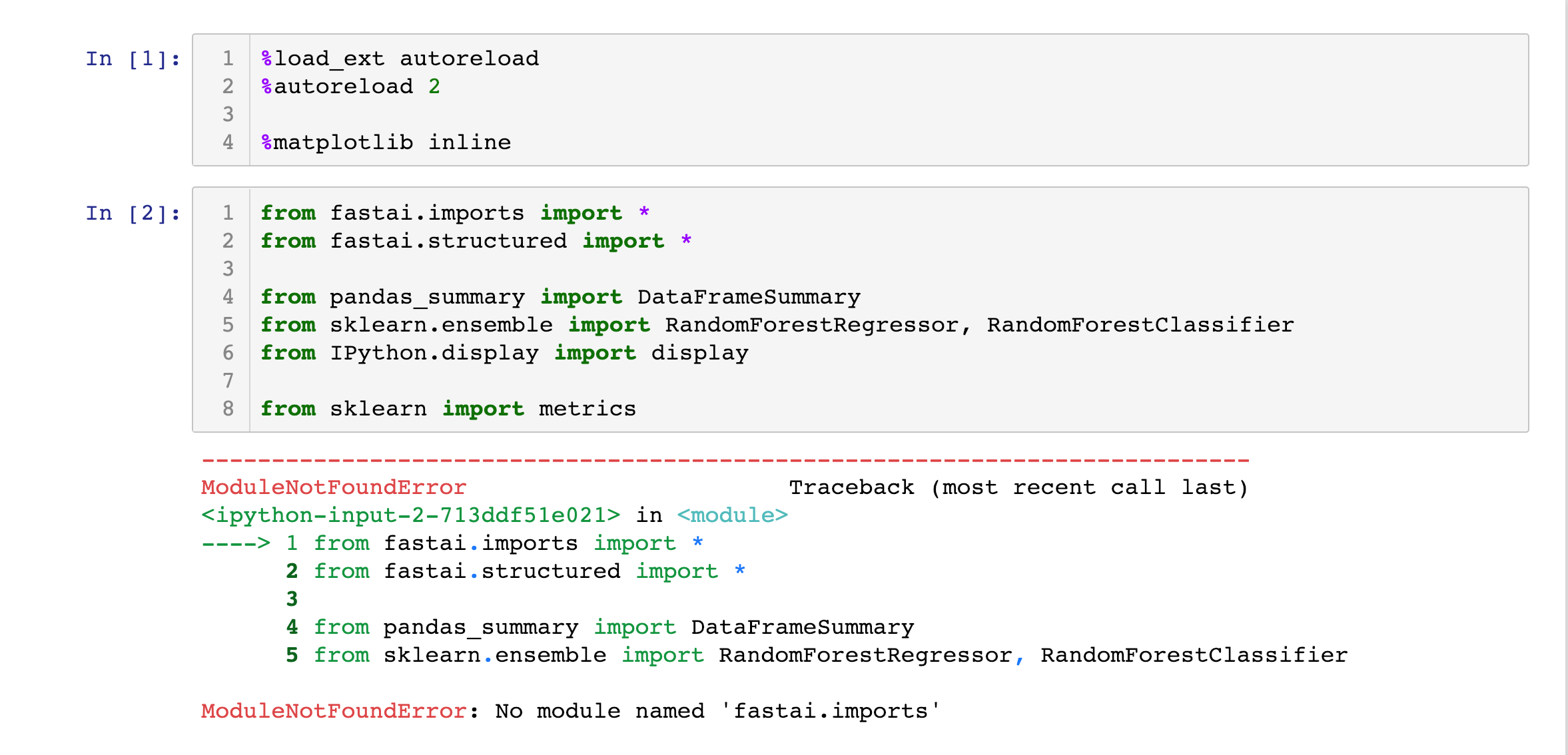
I have not been able to get past the first lesson for over three days. I keep getting this error, and I have tried and tried my best to solve it . Please I need help so I can progress in the course. I have tried it on my local computer and also on crestle I keep getting the same errors for both of them
ModuleNotFoundError: No module named ‘fastai.structured’
Great lecture. I have a question regarding using the proc_df on test data. Let say in the train data, for the variable var1, the categories are [NaN, ‘A’,‘B’, ‘C’]. We do proc_df on train data and we have {NaN:0, ‘A’:1, ‘B’:2, ‘C’:3}. But let say in the test data, the categories for var1 are [NaN,‘A’,‘C’] with ‘B’ non-existent. If we apply proc_df on test, will we get {NaN:0, ‘A’:1, ‘C’:2} which is a mismatch with the train data? Would that be an issue?
Could you please try running the following command in your notebook !pip install fastai=0.7.0
Note: Remove ! from the beginning of the command if you are running pip install in your terminal.
The reason for this error is you might have fastai v1 installed on your system, and the course notebooks were written using fastai 0.7.0. Lot of APIs were updated in v1 and it is not backward compatible.
Also, you can use virtualenv for each project with different versions of fastai if you are using fastai v1 for some other projects as well.
For categorical values, random forest fills in -1 in place of missing values, but for continuous values Random Forest won’t work correctly. Hence, we replace the missing values with median of that particular column.
There are multiple ways to fill in missing values, here we have used median value of the column. One can use mean or any other aggregation as well.
I can see many various errors people getting with setting up ML course environment. I successfully reproduced about dozen/half of them:-) (e.g. ModuleNotFoundError: No module named ‘bcolz’)
Comparing to DL courses which you just start and it works, this one I followed instructions and various tricks and it never fully fix it, just get yet another error after error. I did start from new DL Ubuntu image on AWS (used p2large), got new instance for several possible solutions.
I was wondering if there is somewhere a clean copy (container?) of the course, even if it has older dependencies (fastai 0.7 whatever…) until we have a working new version that would be great…
Hi everyone,
I’ve got a question about how you would handle it if in your train and test data set different columns have NaN in them or not. I used the Kaggle data from the housing price competition. In the training data column A has no NaN inside and column B also not but in the test data column B has a few NaN inside therefore proc_df creates the column B_na. Now the test data set has one column more and can’t be used.
To make it work I just dropped all the feature_na columns proc_df created in the test and training data set. What better way would there be? Create a _na column for every column with only false inside if no value is NaN?
 As mentioned, there is just a handful of helper functions required (at least for the random forest portion of the course), so I think it would not be hard to keep it working / alive.
As mentioned, there is just a handful of helper functions required (at least for the random forest portion of the course), so I think it would not be hard to keep it working / alive.