Absolutely exceptional analysis! Yes you’re totally right. I’d noticed that our “hand made” network was consistently 1% or so less accurate than the pytorch one, and this is the reason why - we’re not normalizing our softmax correctly! It’s really interesting to see how well SGD manages to work around this problem and find an “ok” solution anyway. But switching to your corrected version lifts the accuracy up >92%
Really well done. I’ve updated the notebook and pushed the code. I hope you’ll keep sleuthing, I find all the other bugs I’ve hidden in the code…
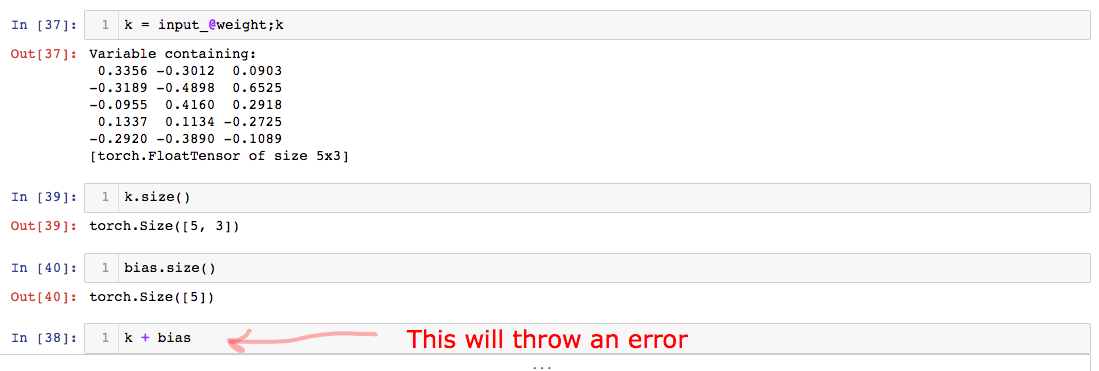
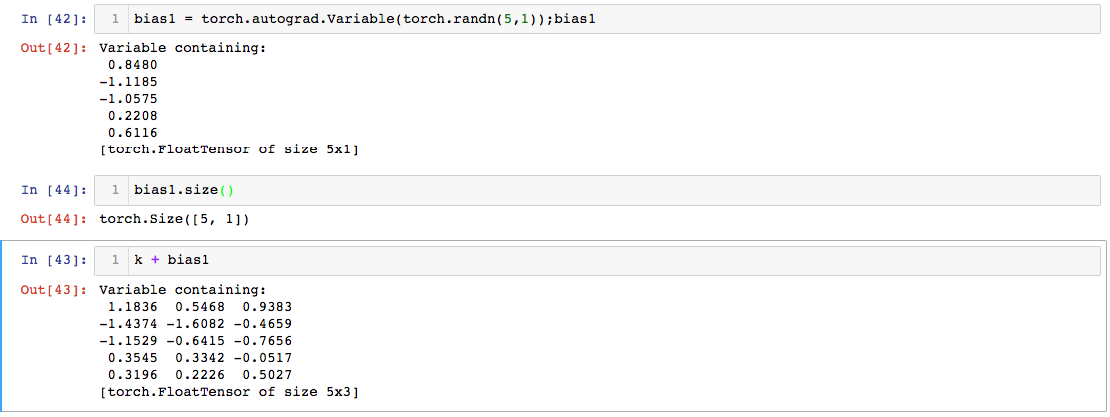
So if we look at the size of bias and bias 1 we can see that bias is actually rank 1 tensor of size whereas bias 1 is rank 2 tensor 5*1. If we follow the broadcasting rules it is clear that bias will not work as the trailing dimension has to be either 1 or the same as the other tensor.
input@weight : 5x3
bias : 5
bias 1: 5x1
But the doubt still remains then why is it working in the custom network that we are using below:
OK you’re on the right track. Let me now show you the key to debugging questions like this - which is to learn to use the python debugger
First add this import:
from IPython.core.debugger import set_trace
Edit the definition of forward() to make this the first line:
set_trace()
Now call you model in the usual way. When python hits the line you added, it’ll open a python debugger session inside your notebook! You can now follow the instructions here: https://github.com/spiside/pdb-tutorial
Let me know if you need any help using the debugger, understanding it’s output, or solving your problem… And if you solve it, tell us what you learnt!
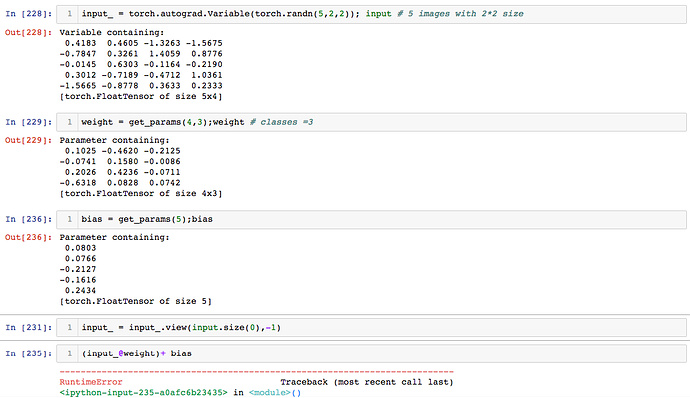
My input was a batch of 5 images with size 2x2 which I have flattened to 5x4 tensor (each row representing an image). I have considered 3 classes so dimension of my weight matrix should be 4x3. So the shape of input@weight should be 5x3…basically 3 probabilities for each class for each image. Now the mistake was I had assumed the size of the bias to be equal to 5 (number of images) but it should be equal to the number of classes i.e 3. This makes sense as bias should not be varying with images but with class. Hence bias of shape 3 will be compatible while adding it to the input@weight product.
This mistake actually stems from another notation that I had seen in some of the online videos where we take weight@input rather than input@weight which is exactly the same but in the former bias has to be a column vector (rank 2 tensor) whereas in the latter it has to be a row vector.
Bottom line: Number of elements in bias = Number of classes
Hi guys, a bit late to the party, but it looks like the NN has extra layers than the simple one described in the class notes? I believe it was previously just a nn.Linear(28*28, 10), nn.LogSoftmax() but now is as below:
Could anyone share insight into this network setup? Specifically why the extra layers were added and why 100 was used?
EDIT: For anyone else following at home, this NN is explained in the next lesson (9), the notebook appears to just have been saved after lesson 9 at some stage.
The Intro to Machine Learning Course runs on an older version of Fastai. fastai refers to fastai v1 as of now(which will very soon be replaced by fastai v2). And it’s not reverse compatible. So you might have to change your environment to run fastai v0.7. Hope that helps!





{kind=link}