When you’ve unfrozen the model and set differential LRs, the (quasi-) optimal LR could’ve been changed, compared to the previously frozen model, because the actual trained model is different: previously it was a logistic regression, and now it’s a full-fledged neural net. Therefore, it’s better to find a new LR. I guess the new LR will change by a greater amount if the differential LR coefficient is greater (that is, my hunch is that [lr/9, lr/3, lr] will have a greater impact on the new LR than [lr/100, lr/10, lr]). It’s actually an interesting question to study.
Here is an image of what happens when overfitting.
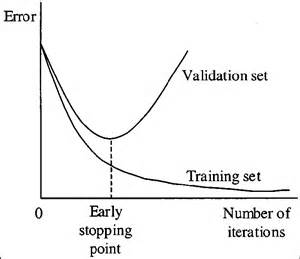
Taken from this link
https://elitedatascience.com/overfitting-in-machine-learning
2 Likes
Thanks @emilmelnikov. So calling lr_find() on the current state of the model is fine? I ask because I don’t understand what the learning rate finder is doing and whether it is changing the state of the model when we execute the lr_find() method on it.
It shouldn’t change anything, but we can always look at the code:
def lr_find(...):
self.save('tmp')
...
self.load('tmp')
So, yes, it saves the model, “trains” it in order to find a good LR and then loads the previous state. It’s very nice that the fast.ai’s code is super readable and transparent.
Ah perfect. Definitely will spend more time studying fastai’s source code.
One final set of questions @emilmelnikov (since you are on a roll): to train the full network in step 8, do we simply run learn.fit(new_lr, 20, cycle_len=1, cycle_mult=2) on the currently unfrozen and precompute=False with the new learning rate until it overfits?
Once we know the epoch at which it overfits, this then becomes the number of epoch we set the final training on the full dataset (where we combine the data in train and valid folders). This I guess becomes the final step. Have I understood this step correctly?
I really appreciate your help with this. I’m trying to understand the details of the entire workflow so I can use it for other projects.
I’m not sure that you can mix training and validation sets in such a way. All I know is that you can use k-fold cross-validation if you really want to utilize all available data. You should ask an experienced Kaggler how to do what you want.
Also, learn.fit(new_lr, 20, cycle_len=1, cycle_mult=2) will train your model for
2^20-1 ≈ 1 million epochs. I guess it’s better to babysit the training process by training the model for, say, 100 epochs, then look at the results and repeat if needed. Alternatively, you can write a simple wrapper loop that trains the model for a bit, looks at the difference between the training and validation losses and decides whether it needs to repeat the training.
1 Like
Looks like this is permissible: machine learning - Training on the full dataset after cross-validation? - Cross Validated
Oops—I just reviewed cycle_mult and realized this. Thank you for all the suggestions. These are all very helpful.
1 Like
I am able to set-up the 2018 part 1 instance on AWS also able to run Jupiter notebook from command line …but when I am running the url in the browser it is saying cannot found the page.
http://my.instance.ip.address:8888/?token=e21c9b842a251354edf58d733acdd2c3f391b13b39ea35c1
Any clue how to resolve the same.
able to resolve the issue…
Thanks, I’ve read the link, and they provide quite reasonable explanation. However, I’d still save some data for the test set (with labels), so that you can report a final loss and/or some performance metric of the model (e.g. accuracy). So, is a sense you still should hold off some of your data. Otherwise, how can you measure quality of your model?
I guess an exception can be made for Kaggle competitions, where you don’t have a labeled test set, but can get the performance of the model in a competition leaderboard after submission. However, in this case the real test set (part of it) is held out by Kaggle.
It’d be great if someone more experienced than me explained how to do a proper train/validation/test split, when it’s OK to use parts of validation/test sets in training, and other related topics. It seems like a simple topic, but I fell like it has many quirks that are not obvious. For example, there is a recent reddit discusssion on a “global overfitting” to sample datasets like MNIST, CIFAR10 or ImageNet in research papers.
You may want to check the above Kaggle API to download datasets directly to your machine. You need to simply download the kaggle.json file from your account in kaggle
i
1 Like
Question: In lesson 2 “Easy steps to train a world class image classifier” why do we perform step 3 if we were to set precompute=false for step4 anyway?
I was wondering if the anyone has tried AWS g3.4xlarge. I wonder if it performs better than the p2.xlarge since it’s newer and the VM is offered with larger RAM and more vcpus.
I got it to work with the .pth file.
Can someone explain this a bit more to me? I understand it has to do with whatever NN model we are usuing (arch=resnext101_64). But can someone elaborate on what exactly this file does?
Did accuracy work for you? I seem to be getting an error where Torch yells at me as it expects the input arguments to be Torch tensors / datastructures. I was able to get it to work using accuracy_np() which I noticed was used in lesson1.ipyb
Edit - I was able to only use accuracy by wrapping the 1st argument in torch.tensorFloat and the second in torch.tensorLong. I’m not sure if the supported types in pytorch changed or if they stopped auto converting numpy arrays internally, but some of the old code that passes in np arrays into accuracy doesn’t work any longer.
Is there a way to save intermediate weights for models during training at regular intervals, or for example, at the lowest learning rates when using CLR? That would be very helpful when setting up long training runs as I’d hate to lose all progress during long runs in case I had to stop training or something goes wrong midway.
1 Like
Yup it’s a decent option, although it’s only 8GB GPU RAM IIRC.
Yes, I’d like to know this as well ! It gets tiring to have to train from scratch every time I open my Jupyter notebook
what if you break up ur training runs to less epochs, and insert the code to save weights in between ? It would be less elegant/ more code, but it should do the job 
Hello, fastai-ers!
I’ve got a question, hope someone could help me out. Thank you in advance!
I have prepared my script for dog breeds example.
Before i do any training, i ran learning rate finder, and it shows this:
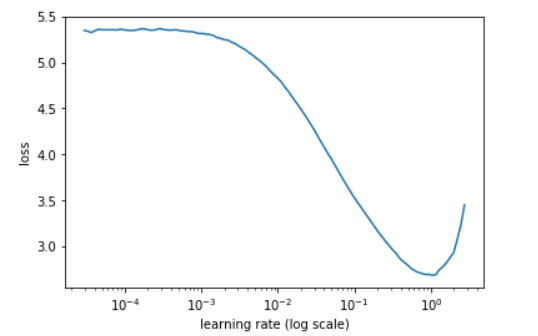
Based on that, i choose LR = 1e-1, and run 3 epochs with precompute, and 3 epochs without precompute:
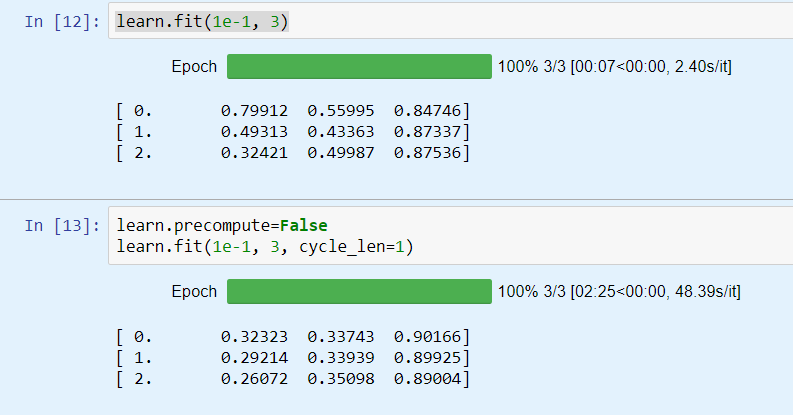
Quite fast my model starts to overfit.
If i re-run it all with LR = 1e-2, results are somewhat better:
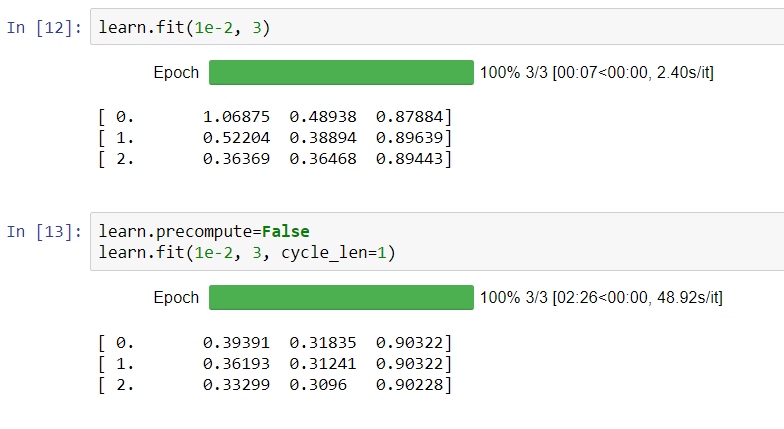
Is there anything i’m missing about LR finder method ?