Is there an alternative to Paperspace that does not require weeks of waiting to get access to the GPU instances?
Crestle is a quick and easy alternative to Paperspace @nyxynyx
Google Cloud Compute is a good option. I follow this guide last week https://medium.com/@howkhang/ultimate-guide-to-setting-up-a-google-cloud-machine-for-fast-ai-version-2-f374208be43 to setup the platform for this course and it works well. Just one thing is that it took 2-3 days waiting Google to approve GPU quotas request but you gonna got 300$ credits free which is 300 hours, enough to explore the course.
2 Likes
Thanks for your response.
The notebook does a “!pip install fastai” at the beginning. So perhaps the package needs to be updated at the source.
In my case, I see log_preds is 2D array and probs is 1D. I understood what the error was hence replaced probs with log_preds and everything worked. Just need to figure out now if with that change it is working as intended.  Thanks.
Thanks.
Found it perfect to listen to that CNN Mini Episode while training my network!
I set up Paperspace yesterday and there was actually very little time needed.
It took me 2 tries though. The first one got stuck loading when trying to open. I removed that one and created a new machine, that one loaded up in seconds.
Hello all,
Just to share one more experience with paperspace - I signed up today around 6 hours ago, tried to set up a machine with no luck so far. After couple of hours of waiting I created a ticket to support, and that’s the info I got from them recently by email:
Thanks for reaching out, and apologies for the delay on your request. Typically we’re able to get users approved within a couple hours With a surge in requests for these instance types, we’re a little behind. We’re in the process of adding capacity right now, so please sit tight and you’ll get a notification the moment a seat is available. We appreciate your patience!
So, waiting…
Hope this helps.
P.S. Meanwhile setting up crestle took 2 minutes and 3 clicks, and allowed to successfully go through the 1st lesson ![]()
I have questions about cell 15 from the Lesson1 Notebook about precomputed activations.
# Uncomment the below if you need to reset your precomputed activations# #shutil.rmtree(f'{PATH}tmp', ignore_errors=True)
-
Why does
learn.fit(0.01, 2)in the next cell execute faster with precomputed activations and slower if I executeshutil.rmtree(f'{PATH}tmp', ignore_errors=True)? Isnt it running learn.fit on the same data in either case (i.e data from dogscats/train) -
If I delete the precomputed activations, how do I get them back? Do I have to do a fresh download of the “tmp” folder from the paperspace script?
-
Just to clarify using precomputed activations - our network has already learned weights using a large image data and we are going to fine-tune them using our “train” folder. Correct?
Thanks a whole bunch
Vikas
1 Like
My models folder is blank. Did anyone else have the same issue?
I am assuming it should not be blank because this is the “pretrained” model we start with in Lesson 1 yes?
Hi,
First let us explained the idea of precomputed activations
Let’s go back to the network, consider resnet50.
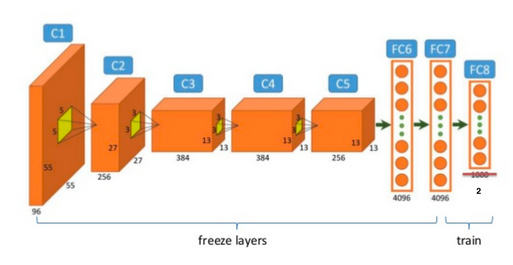
When finetuning a model we train only the last layer and previous ones (freeze layers) remain unchanged. So all computations on the freeze layers will be the same ie: the result of image 1 (of my training set) going from C1 to FC7 layers will never change or we do it many times with same images. In fact an epoch is a tour over all images of the training set so training during 10 epochs means I’ll do the same computation 10 times. This is a waste, so we take a shortcut, we precompute all training image results from 1st to last fixed layers, here from C1 to FC7 and save them: this is the precomputed activations. In doing so it’ll be fast because we’ll use results of fixed layers computations (precomputed activations) and compute only from FC7 to FC8 for each image.
So the question 1:
The response is clear, it will take much time because it’ll apply all fixed layers to all training images. But the next times will be faster.
Question 2:
No, you have to run fit but make sure to use the attribute precompute=True:
learn.fit(0.01, 2, precompute=True)
Question 3:
Precomputed activations and pretrained weights are two differents things.
Precomputed activations help speeding computations during training a network while pretrained weights are like the level of knowledge acquired by the network after some training on some data.
Hopefully, it helps.
4 Likes
I have tried distinguishing between flying birds and flying planes. It worked perfect. 98% accuracy 
Where is located your models folder? if possible show us the full path.
Yes absolutely. And thank you for responding.
it is located in /data/dogscats/models
The Lecture Notes suggested that ResNet model will be downloaded and I did not see that when I ran the Lesson1Jupyter Notebook (hence the confusion). Search for “Let’s run the Model!” in the Lecture Notes you will see what I mean.
The confusion also stems from the fact that the Lesson1 notebook says we use “pretrained model” but I dont see it anywhere on the disk to be able to use it.
I see. Let me see if I can rephrase it (confirm if I am understanding this right)
Let’s say that C1-FC7 are represented by the equation y= wx (x is the input image, w is the weights and y is the result aka activation)
If we did not save precomputed activations before, we “precompute” y i.e. we compute y first time an image x passes through the network. But, everytime after that we do not compute y but use the cached values saved in the tmp folder.
And last but not the least, the weights w.
Our jupyter notebook uses a pretrained model i.e. w learned from some other data sets. As we train it on our data set, w’s get updated but the starting point was the pretrained model we began with?
Is that accurate?
(Thank you very much for investing your time and giving a detailed reply)
Hello Rachel,
Thank you for the summary post. Helps me keep my thoughts organized. I have one quick question
In Lesson 1 video, Jeremy asks us to download images of our choice from google and try the image classification. My worry is that if we download say 100 images (and use 50 to train, 20 for validation, and 20 to test) - wouldn’t the model over fit?
Perhaps I am missing something - What is the purpose of trying our own data?
Is there a number of images you recommend ?
Thanks
Vikas
Could you share the number of samples you used for train/validation/test ?
For the training set I have:
Birds: 409 images
Planes: 322 images
For the validation set I have:
Birds: 146 images
Planes: 80 items
I have grabbed images from flickr.com
2 Likes
In the lecture Jeremy Howard gives examples about cricket and baseball with 10 images, but personally I think you should try with more images.
The purpose of training our own data is to see for what kinds of images we can use this pretrained model. And besides that I found it more interesting when you train own model and see for which images model gave incorrect labels. Beside that with our own images we need to fine tune some hyparameters.
1 Like
They did not ask any verification. I just followed this https://github.com/reshamas/fastai_deeplearn_part1/blob/master/tools/paperspace.md
And you can use FASTAI15 credit code for paperspace. For me it took about 5-7 minutes.
Thank you