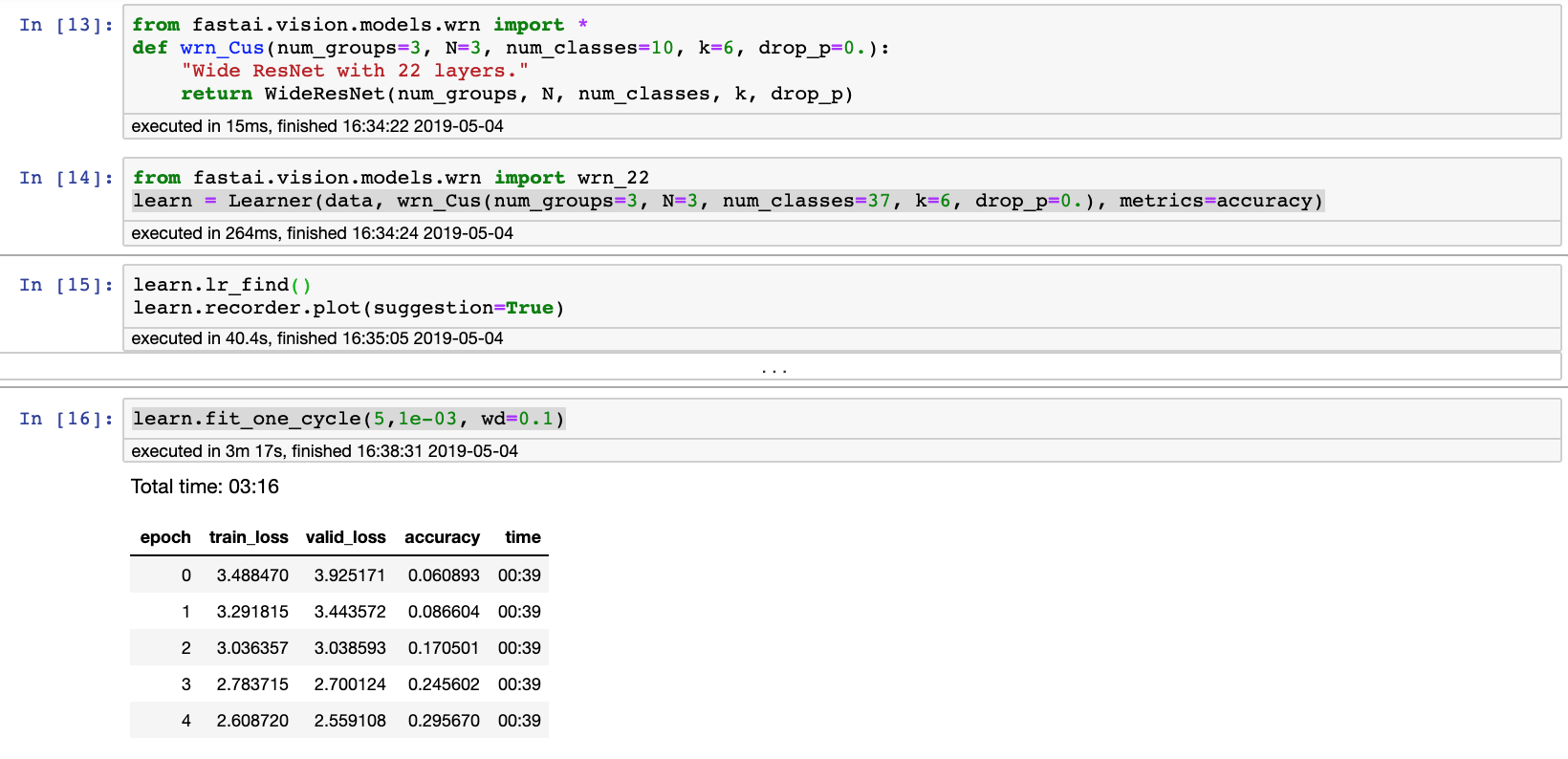
I am trying to implement WideResNet for a project and kept getting the following Cuda error.
RuntimeError: CUDA error: device-side assert triggered
Which as sgugger explains is a generic bad index.
Any idea of how to problem-shoot and solve? I have tried:
- Resetting everything (Did you turn it off and on?)
- Googled most are (Masking off,
- Re-updating everything
- Running it in lesson1-pets
- Reducing batch-size to 10
I took a screenshot in lesson1-pets. While Resnet still works, WRN_22 has the device-side assert triggered.
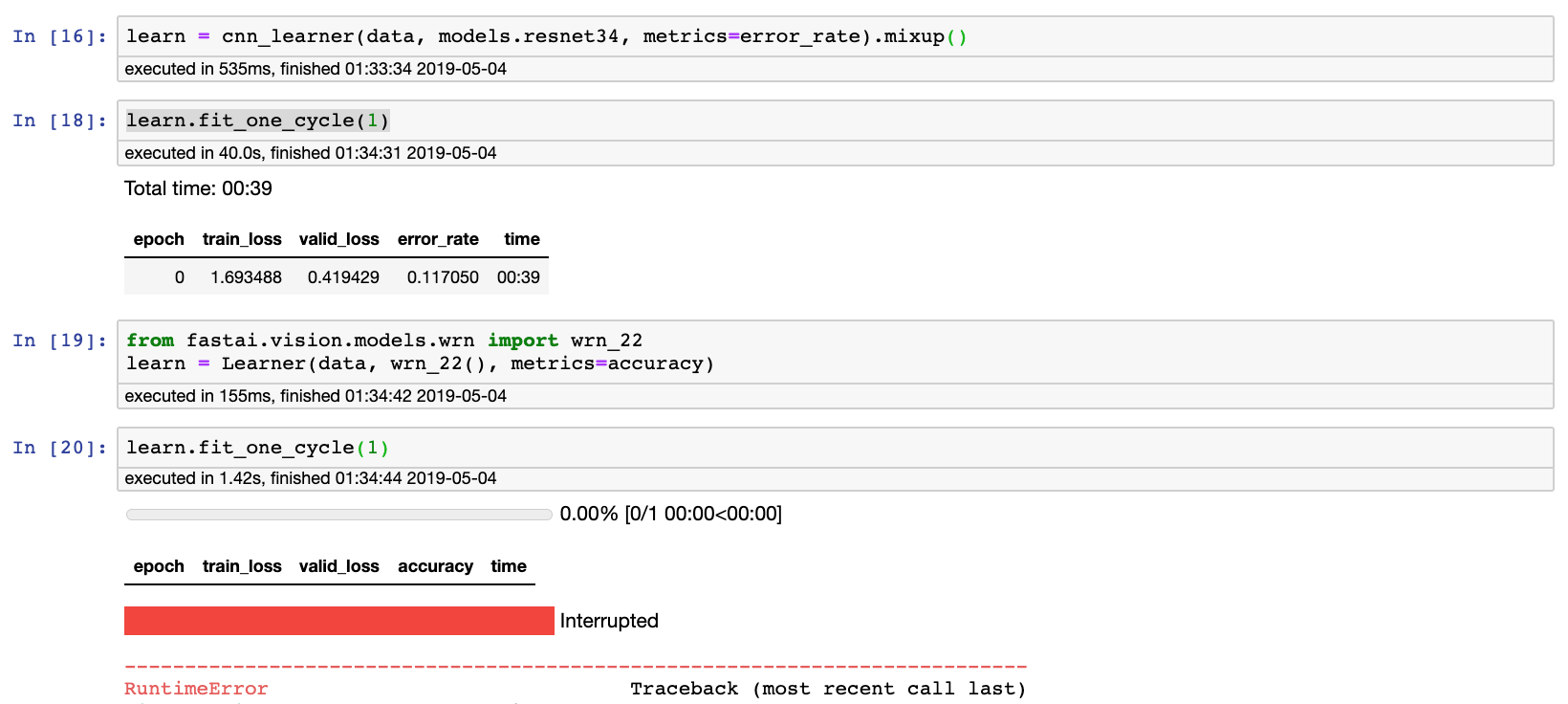
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
in
----> 1 learn.fit_one_cycle(1)
~/anaconda3/lib/python3.7/site-packages/fastai/train.py in fit_one_cycle(learn, cyc_len, max_lr, moms, div_factor, pct_start, final_div, wd, callbacks, tot_epochs, start_epoch)
20 callbacks.append(OneCycleScheduler(learn, max_lr, moms=moms, div_factor=div_factor, pct_start=pct_start,
21 final_div=final_div, tot_epochs=tot_epochs, start_epoch=start_epoch))
---> 22 learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
23
24 def lr_find(learn:Learner, start_lr:Floats=1e-7, end_lr:Floats=10, num_it:int=100, stop_div:bool=True, wd:float=None):
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
197 callbacks = [cb(self) for cb in self.callback_fns + listify(defaults.extra_callback_fns)] + listify(callbacks)
198 if defaults.extra_callbacks is not None: callbacks += defaults.extra_callbacks
--> 199 fit(epochs, self, metrics=self.metrics, callbacks=self.callbacks+callbacks)
200
201 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, learn, callbacks, metrics)
99 for xb,yb in progress_bar(learn.data.train_dl, parent=pbar):
100 xb, yb = cb_handler.on_batch_begin(xb, yb)
--> 101 loss = loss_batch(learn.model, xb, yb, learn.loss_func, learn.opt, cb_handler)
102 if cb_handler.on_batch_end(loss): break
103
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in loss_batch(model, xb, yb, loss_func, opt, cb_handler)
31
32 if opt is not None:
---> 33 loss,skip_bwd = cb_handler.on_backward_begin(loss)
34 if not skip_bwd: loss.backward()
35 if not cb_handler.on_backward_end(): opt.step()
~/anaconda3/lib/python3.7/site-packages/fastai/callback.py in on_backward_begin(self, loss)
288 def on_backward_begin(self, loss:Tensor)->None:
289 "Handle gradient calculation on `loss`."
--> 290 self.smoothener.add_value(loss.detach().cpu())
291 self.state_dict['last_loss'], self.state_dict['smooth_loss'] = loss, self.smoothener.smooth
292 self('backward_begin', call_mets=False)
RuntimeError: CUDA error: device-side assert triggered