When I read some papers.
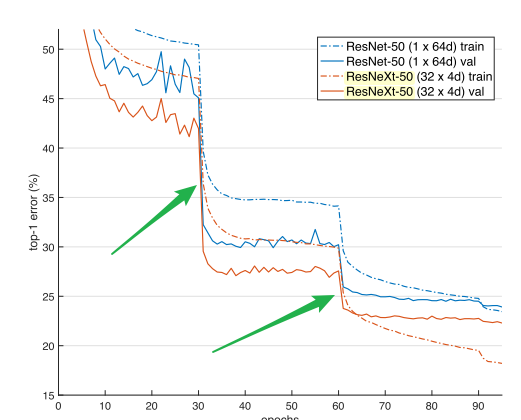
The training plot all like this - error was stuck for many epochs but suddenly decrease so much.
I can not figure out the reason.
Someone on internet call this optimization landscape.
And Someone said this because LR decay.(But I never got such big improvement from LR decay, is it because I didn’t train enough epochs??)
This is a pattern that is seen if you train with piecewise constant learning rate. A very common schedule used in papers on CNNs is training for some number of epochs with a lr of 0.1, then going to 0.01 and later on to 0.001. Assuming you have spent enough time in each of the stages, you should see the loss falling as on the graph.
What is happening there and why that is the case is not easy to answer. At least I am not aware of any definitive answer of why this is happening. Part of the reason is probably because it is quite hard to put your finger exactly on what happens to the weights during training. But building up an intuition on this helps a lot. There are quite a few papers on related phenomena out there and I would start with reading the papers by Leslie Smith.
Part of the story likely is that in the flat portions of the graph we are traversing the weight landscape looking for a relatively flat area at the given ‘resolution’ of the environment we care about (as dictated by the lr). Once we find that general area, we are able to start looking and fitting to finer details.
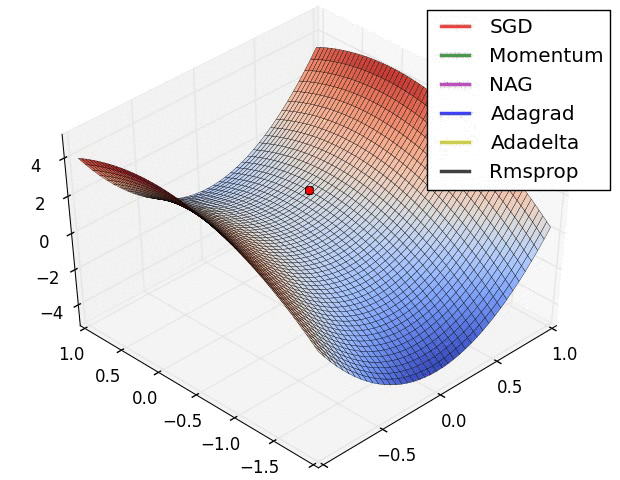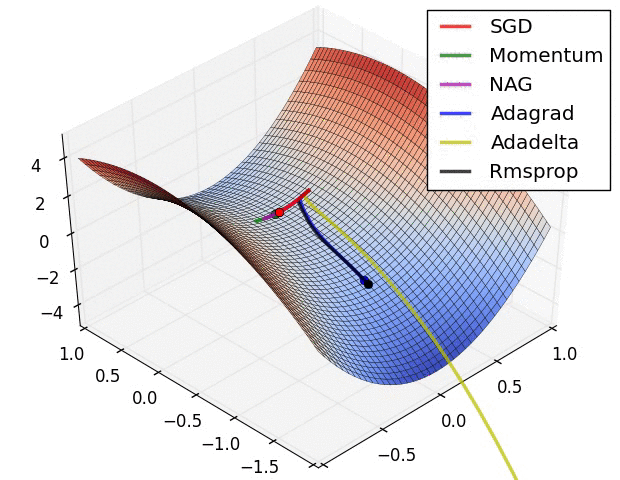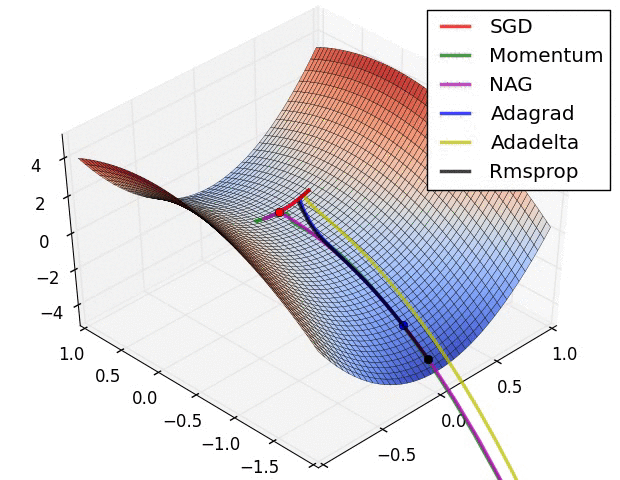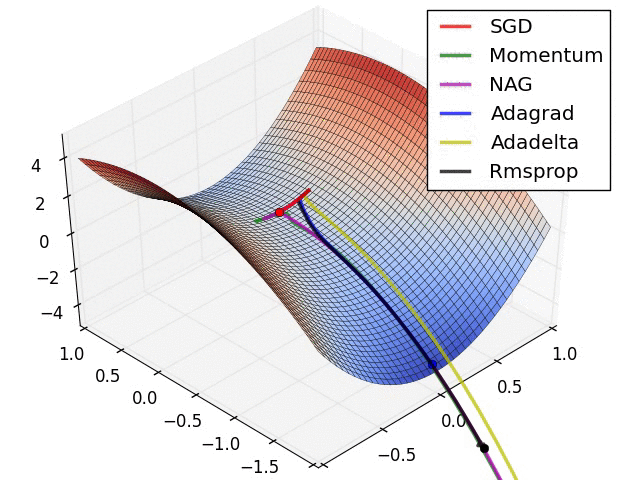
The animation that you included shows how gradient descent works and build the understanding of what it does really, really nicely, but once we move to higher dimensions (and CNNs can easily have 60+ mln parameters!) things start looking a little bit different, at least as far as I understand. The basic mechanism of going downhill is used but as far as I understand just going downhill all the time would not get us very far. We are not necessarily looking for the configuration in the weight space that gives us the lowest loss, but one that we can reach with some feasibility and one that holds the promise of generalizing to unseen data. I might be imagining the high dimensional weight space wrongly, but the intuition that helps me is that the terrain is much more rugged than in the 3d animation you share above and that the learning rate changes the resolution at which our optimizer can perceive its surrounding.
I wrote this post on medium some time ago when thinking a bit about this - maybe you will find it helpful.