Hi,
to better understand “moving parts” of NN architecture I created a simple toy-problem using sample of sinus function.
I already asked that question here but with no success: https://stats.stackexchange.com/questions/284203/why-relu-activation-cannot-fit-my-toy-example-sinus-function-keras
I have a toy example of modeling sinus function using simple FC layer NN. My input data is just 150 data points uniformly randomized in range from 0 to 10.
I started from fiting NN using tanh activation with following architecture:
model = Sequential([
Dense(10, input_shape=(1,), activation='tanh'),
Dense(1),
])
model.fit(dataset_x, dataset_y, batch_size=32, validation_split=0.1, nb_epoch=10000, verbose=0)
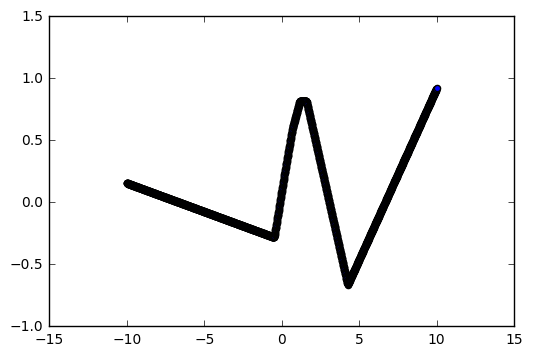
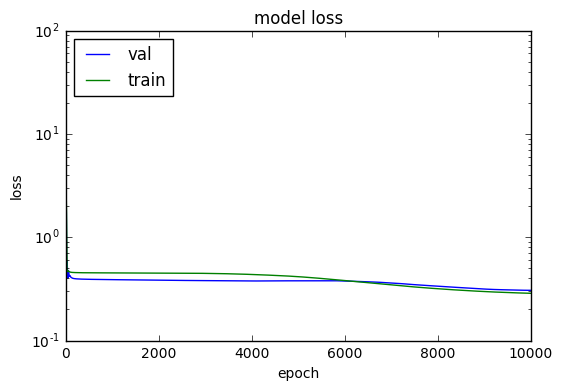
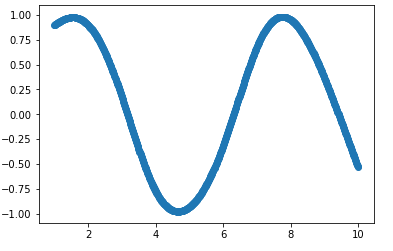
It took 10000 epochs to get fit like this:
tanh activation fit after 10k epochs
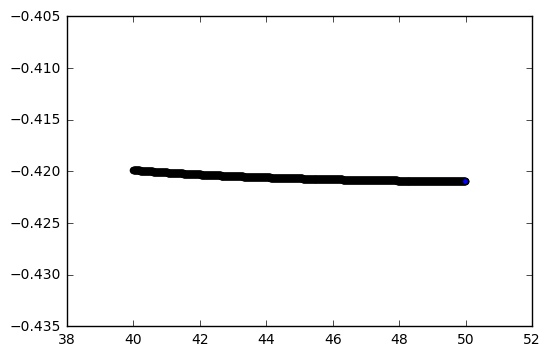
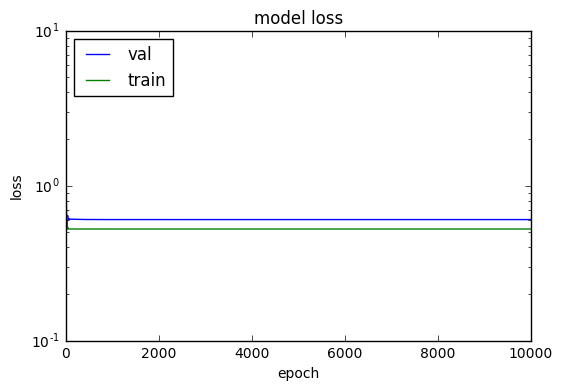
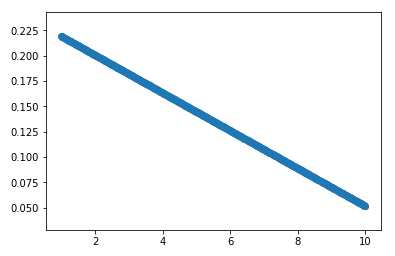
Running the same code but switching only activation from tanh to relu cannot converge at any fit. Not even for 20-30k epochs.
ReLU activation fit after 10k+ epochs
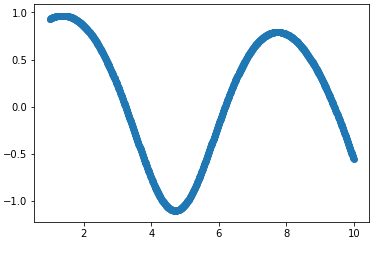
However if I switch to softened ReLU (softplus) it somehow fits but requires at least 2x more epochs to fit anything close to the result using tanh.
Softplus activation fit after 20k epochs
So the general question is why this happens?
Additional questions/thoughts I have are:
-
Does it have anything in common to the fact that the shape of tanh and softplus functions is curved and ReLU is just two linear functions bound together?
-
Maybe ReLU requires some different architecture of NN to work here, or maybe using some regularization (I tried some L1, L2 but did not helped) or any other kind of modificiation because it just canot model non-linear functions using this architecrtre I have (I tried adding more hidden layers without luck).
I am really missing here some intuition why this happens, as ReLU is advertised as the best/fastest activation that should be know used by default in any NN.