In Andrew Ng’s Coursera course, he recommends performing batch-norm before ReLu which is the popular practice. I don’t see why its not better after.
Technically batch-norm can normalize to any mean and variance so it shouldn’t matter, but isn’t it easier to normalize after as we want activations to have variance 1?
Why is it better to normalize before activation function?
1 Like
Interesting question! I paused on it and realized I don’t have a good answer, only some intuition. I wonder what is the impact on gradients, maybe someone more mathematically inclined can comment 
My intuition is that applying BN after ReLu might change the sign on some activations, from positive to negative, and that it may not be a good thing… but I may be totally wrong, so interested in others’ thoughts!
1 Like
Hi @akashgshastri,
The fact of applying batch norm before ReLU comes from the initial paper presenting batch normalisation as a way to solve the “Internal Covariate Shift”. The are lots of debate around it and this is still a debate whether or not it should be applied before or after the activation :
In practise, applying it after the activation seems to lead to better results though.
Hope it helps !
Charles
2 Likes
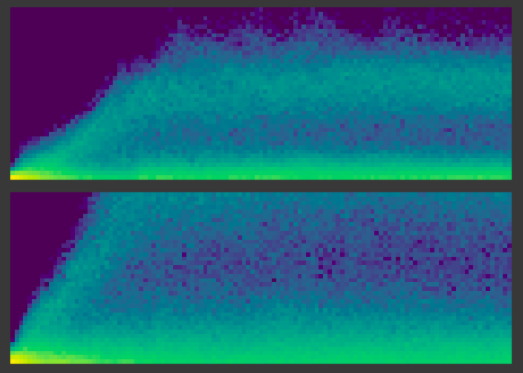
An interesting coincidence - soon after responding to this thread, I encountered this topic while reading Jeremy and Sylvain’s book, in chapter 13. I used the code from the chapter to do some experiments, which still keep me puzzled. In the MNIST experiments I’ve done, there isn’t much difference in accuracy when performing BatchNorm before/after ReLU. However, the activation stats look differently. I haven’t yet grasped how these are constructed and what it means - posting these here if somebody has insights to share Here’s the notebook with experiments: https://colab.research.google.com/drive/1DHG-G3qhenCwu_7Pbk50ZerftNuq51Bd?usp=sharing
3 Likes