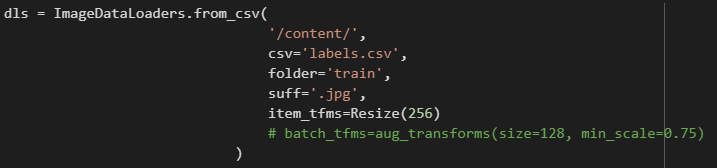
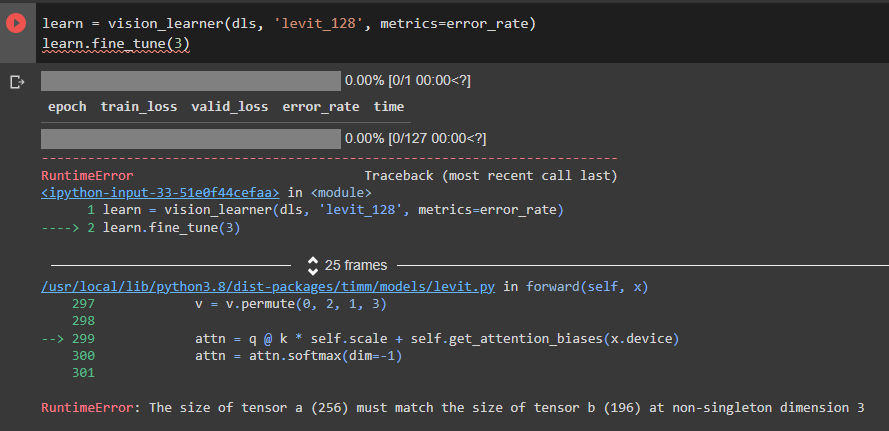
I am trying to use what I learned in lesson 2 of the course and for that I tried several models on the Dog Breed Identification dataset (Dog Breed Identification | Kaggle). When testing with the levit_128 model with image sizes 256
LeViT cannot manage variable resolutions due to its positional encoding mechanism and expects a fixed input size - in this case, levit_128 was trained on 224 x 224 images and thus does not accept 256 x 256 ones. This defect is shared by numerous other vision transformers, such as the original ViT or Swin, and is one of the main disadvantages of this family of networks, albeit certain remedies, like interpolating the position embedding vectors or employing more adaptive positional encoding techniques (e.g., sinusoidal encoding), have been shown to be effective.
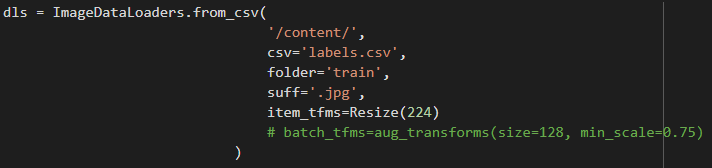
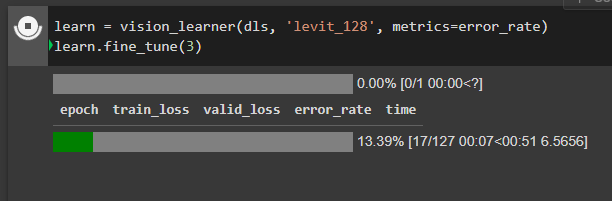
For your task, I recommend either bringing down the resolution to 224 x 224 or adopting another architecture that can handle different input shapes - PVT V2, ConvNeXt, DaViT, … (all supported by timm and therefore fastai) - as your backbone.