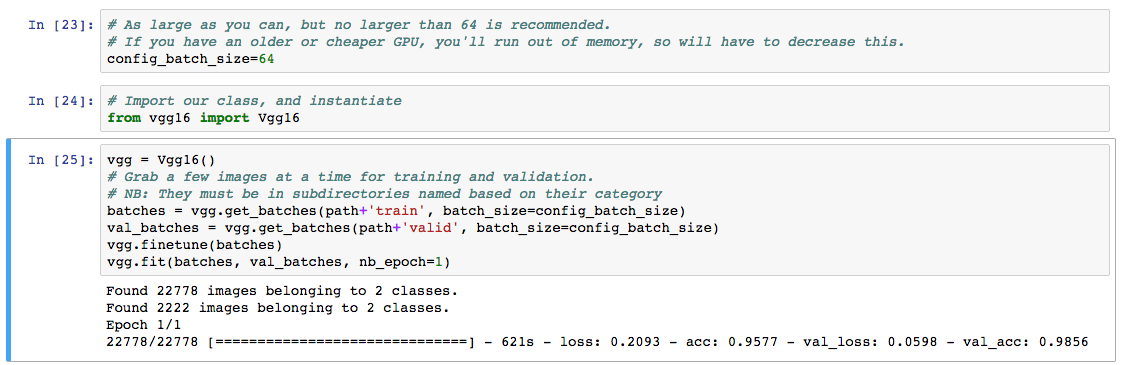
This is strange, as my partner-n-crime @prateek2686 and I have almost exactly the same architecture, yet my epochs are roughly 5 times as long as his!
I’ve tried fiddling wth the layers, with the learning rate, optimizer type, batch size. Nothing I have tried will change the length of the epochs significantly!
Where else can I look for the source of the slowness? Yes I am using the p2.xl (Tesla K80) on AWS…
The code is very straightforward:
model = Vgg16().model
conv_layers,fc_layers = split_at(model, Convolution2D)
del fc_layers
conv_model = Sequential(conv_layers)
# Using the name 'pafs' -- predictions / activations / features -- however you want to look at it
conv_pafs = load_array(path + 'conv_pafs.bc')
val_pafs = load_array(path + 'val_pafs.bc')
(val_classes, trn_classes, val_labels, trn_labels,
val_filenames, filenames, test_filenames) = get_classes(path)
def get_fc_model():
model = Sequential([
BatchNormalization(input_shape=conv_layers[-1].output_shape[1:]),
Flatten(),
Dense(4096, activation='relu'),
Dropout(0.5),
BatchNormalization(),
Dense(4096, activation='relu'),
Dropout(0.5),
BatchNormalization(),
Dense(2, activation='softmax')
])
model.compile(optimizer=RMSprop(lr=0.0001, rho=0.7), loss='categorical_crossentropy', metrics=['accuracy'])
return model
fc_model = get_fc_model()
fc_model.fit(conv_pafs, trn_labels, nb_epoch=8,
batch_size=batch_size, validation_data=(val_pafs, val_labels))