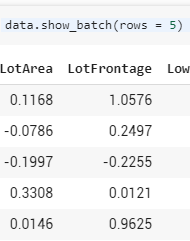
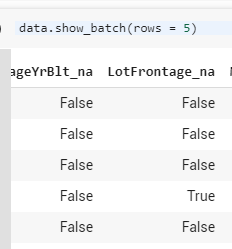
FillMissing (if there are any) will generate a new #na# token whenever a value is missing, and a new column is generated with that variable _na. One example is your ‘LotFrontage’ variable. If we look at show-batch, we see the #na# value there, and the corresponding _na column for if the value was there or was not. I am curious as to why you chose to include “HalfBath” and other ‘numerical’ values as categorical. I’d associate the number of half-baths as a count rather than a category.
Categorify is passed into pandas itself, and essentially it is there to build the embedding matrix if you have categorical variables.
Second, if you look at the lesson 6 notebook, you can see that in order to get our actual predictions back from the regression notebook, we do:
Hello! Thanks for reply
As for how FillMissing works, I think I understand now. However, looking at the values of lot frontage
All the values are there but the column for LotFrontage_na says True for the fourth row when it’s clearly not #na#
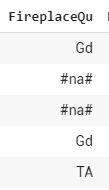
Also, there’s other columns like Alley or Fence and FireplaceQu which look like this
But there’s no FireplaceQu_na column.
To be honest I’m not exactly sure why I had those variables setup the way I did, but I think I seperated them properly now! However the loss’s are still very big.
I also fixed the last line to get the actual predictions but now most of the values seem to be infinity