Now Nvidia is showing everywhere that the performance of their new line is incredible for INT8 and INT4 types. Why this is relevant to us ML practitioners? Most of the work we do is with FP32 and FP16.
I have seen some papers about quantization of NN but is it so good? I also saw a paper about gradient compression and SGD using only signs that looks promising here
Does pytorch have support for INT computing?
Any though @jeremy on this? is fastai looking at this?
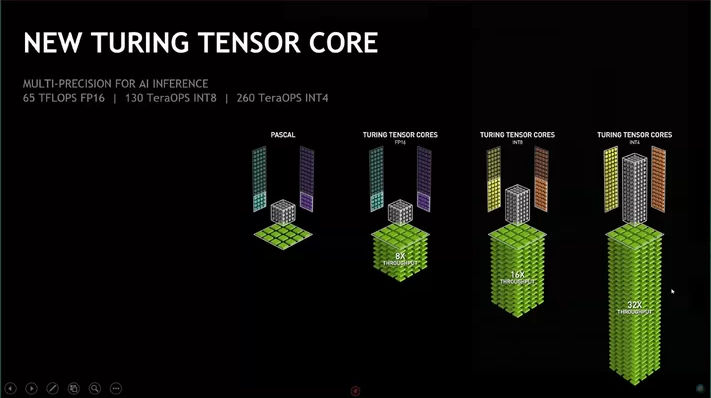
Int4 can be used for inference, so they’re talking about inference speeds
You are right, but it appears that training with some variables as ints is also possible, as described in the paper above.
Just one question, if you feed ints to your NN after passing a non-linear activation layer, the variables are not int anymore, I am right? Even a linear layer will have fp parameters, so I don’t get how inference can be carried out with INT operations.
Yes, this is all about inference. As well as increasing effective computation power, low precision also reduces memory bandwidth - this is as or more important.
INT8 is more common however for non-GPU chips like CPUs, FPGAs or all these dedicated low power ASICs making their way into mobile phones. For these devices, fixed point math is much faster & easier to implement. For instance a floating point multiplier for an FPGA takes a huge amount more space than a fixed point multiplier. You’ll even see some of these devices referring to computation speed in ‘TOPS’ instead of ‘FLOPS’, which is a testament to INT8.
We’ll see how much traction INT4 gets. INT8 is already a bit tricky, additionally many devices such as CPUs don’t have native INT4 instructions.