Why does fastai opt to use the flattened loss of every PyTorch Function? I am trying to wrap my head around this but I’m not getting it.
It’s to avoid you have to flatten each time the shape of your prediction.
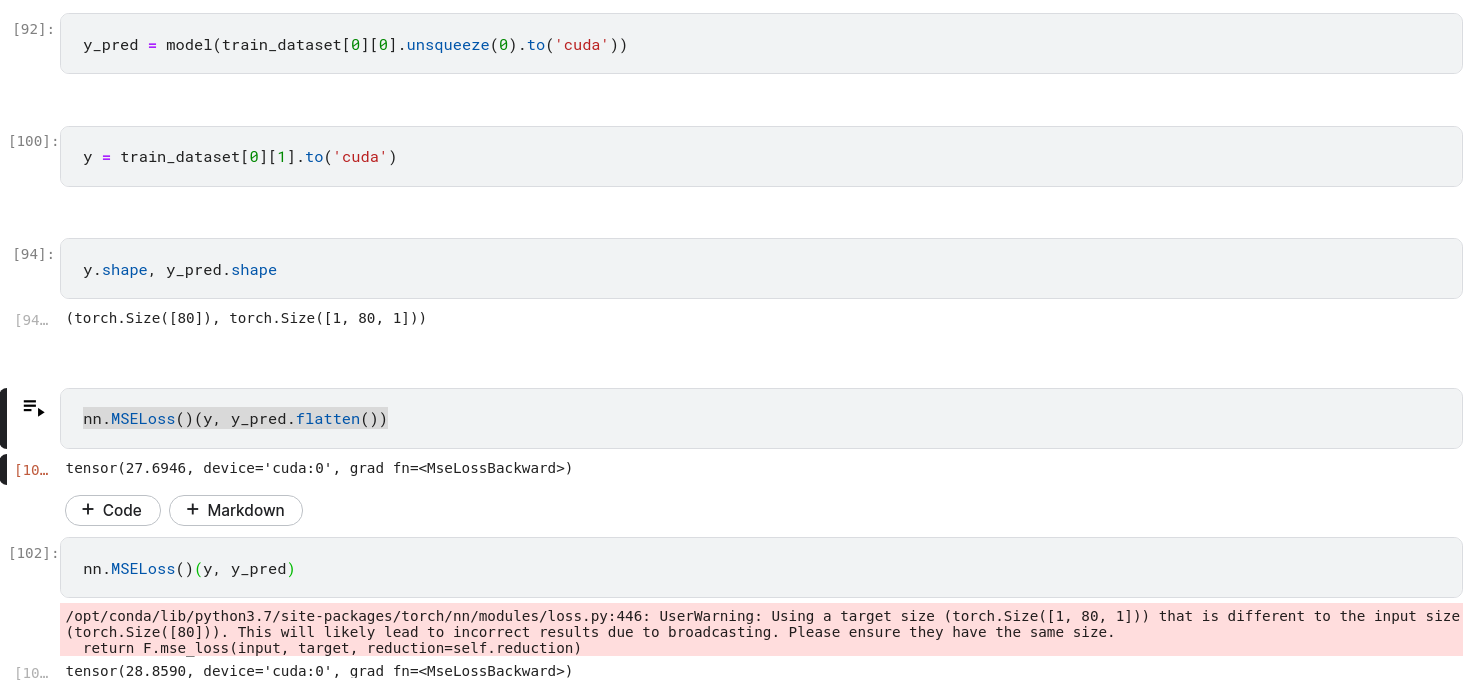
In my example below, you can see when your y_pred has shape (1,80,1) and your y has shape (80). If you don’t flatten your y_pred to have shape (80), pytorch give you a warning and the result is not correct
3 Likes
Ooh that’s neat. Thank you @dhoa
1 Like
Great! Thanks