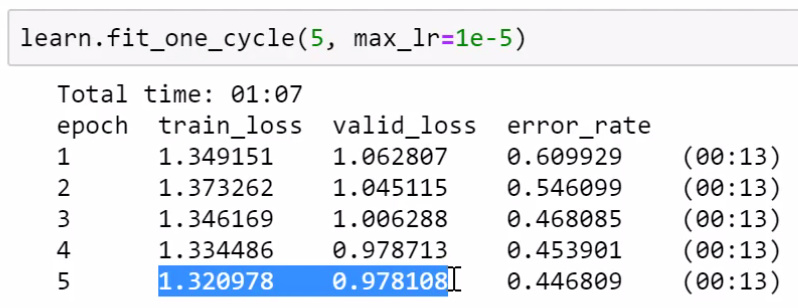
In lecture 2, Jeremy explains, “When training loss is higher than validation loss, it always means that you have not fitted enough. Either learning rate is too low, or number of epochs is too low.” I am not able to understand why that’s the case. Can someone give me some pointers to learn more about this?
From what I understand it’s the following.
The model trains on the training set, and the training loss is calculated on that training set. So this loss is calculated on the same dataset the model was trained on and should thus be low.
However, the model has never seen the validation set, so when the validation loss is calculated it is on new data for a model only trained on the training set.
Hence the training loss ought to be lower than the validation set, because the model was fitted on the same data than the training loss is calculated on whereas it has never seen the validation data. If that’s not the case, something is not quite right with the training. Maybe the learning rate was too low, or maybe the model just needs a few more epochs.
Is that clearer ?
2 Likes
Yes. Thank you!
Another way of thinking about it is that if your training loss exceeds your validation loss then your model has not learned enough to do better on a training set it has seen before than a validation dataset that it hasn’t seen, which is not good. This could be due to having the wrong learning rate or simply not giving the model enough time / epochs to learn the dataset
3 Likes
I’m pretty sure Jeremy will be covering this (training, validation, losses, overfitting etc.) even more in the next lesson. If you’d like to explore on your own, there’s lots of resources available online.
This is also a good one, even though it uses a different type of neural network to make the same point. Good graphs and explanations.
https://machinelearningmastery.com/diagnose-overfitting-underfitting-lstm-models/