Hello everybody, I am struggling with a regression problem where i am trying to predict the temperature of steel using a tabular learner.
DataFrame "df’ holds all my data, which is all of my data. It is from this that I derive
Train, validation and test. The shape is : (11660, 52)
30 % I split to test giving me 8162 for train and 3498 for test. By test, I want this to be
“THE HOLD OUT SET” which the model does not see, it is NOT the validation set which to monitor loss or choice of metric on.
Now, I use the TabularList class and the data block API as follows.
train_data : 70% of 11660 for training.
test_data : 30 % hold out. To obtain my model predictions on.
SETTING EVERYTHING UP
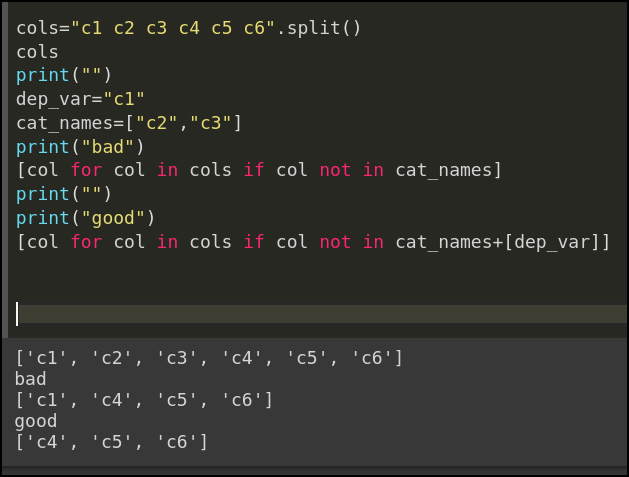
dep_var = “STL_TEMP”
cat_names = [‘col1’, ‘col2’]
cont_names = [col for col in list(df.columns) if col not in cat_names]
procs = [Categorify, Normalize] # my data has not missing values
Data block API time!
test = TabularList.from_df(test_data, cat_names=cat_names, cont_names=cont_names)
data = (TabularList.from_df(train_data, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_rand_pct(0.2)
.label_from_df(cols = dep_var, label_cls = FloatList)
.add_test(test) # ALL PROBLEMS START FROM HERE I GUESS!
.databunch())
When I print out data, I can see that Test set has dep_var as a feature., which is horrfying, I mean my model is predicting my target using my target.
Infact when I trained this model I get 99% accuracy for this precise reason, total bummer, was radically upset😢.
So I removed my target from test_data before I made the test DataBunch. That gave me a keyerror like so, this is for the add_test(test).
KeyError Traceback (most recent call last)
D:\anaconda\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
2645 try:
-> 2646 return self._engine.get_loc(key)
2647 except KeyError:
pandas_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: ‘STL_TEMP’
During handling of the above exception, another exception occurred:
KeyError Traceback (most recent call last)
in
2 .split_by_rand_pct(0.2)
3 .label_from_df(cols = dep_var, label_cls = FloatList)
----> 4 .add_test(test)
5 .databunch())
~\AppData\Roaming\Python\Python37\site-packages\fastai\data_block.py in add_test(self, items, label, tfms, tfm_y)
561 else: labels = self.valid.y.new([label] * len(items)).process()
562 if isinstance(items, MixedItemList): items = self.valid.x.new(items.item_lists, inner_df=items.inner_df).process()
–> 563 elif isinstance(items, ItemList): items = self.valid.x.new(items.items, inner_df=items.inner_df).process()
564 else: items = self.valid.x.new(items).process()
565 self.test = self.valid.new(items, labels, tfms=tfms, tfm_y=tfm_y)
~\AppData\Roaming\Python\Python37\site-packages\fastai\data_block.py in process(self, processor)
82 if processor is not None: self.processor = processor
83 self.processor = listify(self.processor)
—> 84 for p in self.processor: p.process(self)
85 return self
86
~\AppData\Roaming\Python\Python37\site-packages\fastai\tabular\data.py in process(self, ds)
60 return
61 for i,proc in enumerate(self.procs):
—> 62 if isinstance(proc, TabularProc): proc(ds.inner_df, test=True)
63 else:
64 #cat and cont names may have been changed by transform (like Fill_NA)
~\AppData\Roaming\Python\Python37\site-packages\fastai\tabular\transform.py in call(self, df, test)
122 “Apply the correct function to df depending on test.”
123 func = self.apply_test if test else self.apply_train
–> 124 func(df)
125
126 def apply_train(self, df:DataFrame):
~\AppData\Roaming\Python\Python37\site-packages\fastai\tabular\transform.py in apply_test(self, df)
193 “Normalize self.cont_names with the same statistics as in apply_train.”
194 for n in self.cont_names:
–> 195 df[n] = (df[n]-self.means[n]) / (1e-7 + self.stds[n])
D:\anaconda\lib\site-packages\pandas\core\frame.py in getitem(self, key)
2798 if self.columns.nlevels > 1:
2799 return self._getitem_multilevel(key)
-> 2800 indexer = self.columns.get_loc(key)
2801 if is_integer(indexer):
2802 indexer = [indexer]
D:\anaconda\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
2646 return self._engine.get_loc(key)
2647 except KeyError:
-> 2648 return self._engine.get_loc(self._maybe_cast_indexer(key))
2649 indexer = self.get_indexer([key], method=method, tolerance=tolerance)
2650 if indexer.ndim > 1 or indexer.size > 1:
pandas_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: ‘STL_TEMP’
STL_TEMP here is my dep_var i.e Target. I am really confused. If I remove '“STL_TEMP” during prediction, I again get a keyrror. First off the bat, why should the test even require the target, and why isn’t the databunch realizing this even though I passed dep_var = ‘STL_TEMP’.
How should I set up the databuch such that the model does not use “STL_TEMP” as a feature for training. Please help. I am also aware that if I see the y target list for the Test object it shows EmptyList, but it is using “STL_TEMP” to predict “STL_TEMP” right? I even changed the target to 0, 100, and other such values, and the predictions are totally dependent on that.
Thanks very much for helping.