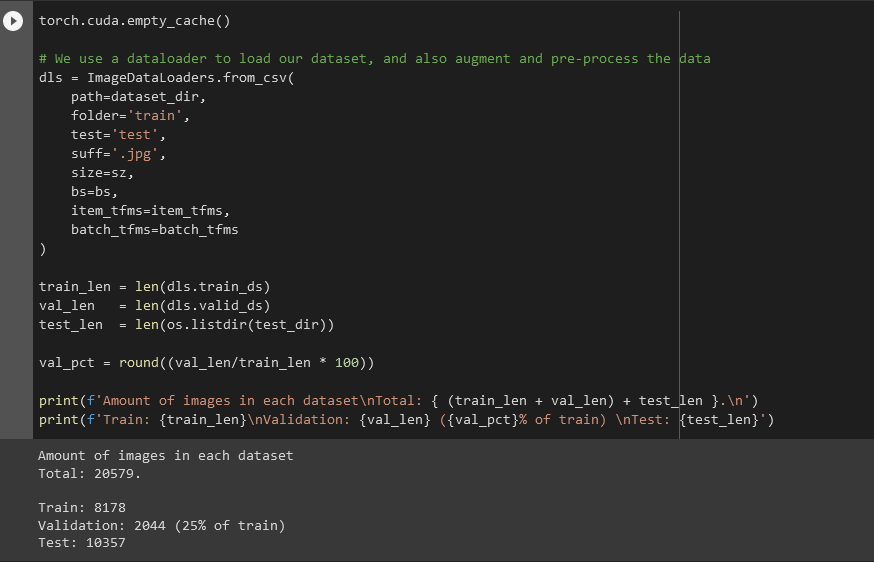
Hi,
I’m using the DataLoaders class to load, and transform my data before training. However when I try to log some stats on the different datasets I find that the validation dataset is split to 25% of the training dataset and not the default 20%. I’ve tried to use valid_pct(0.2) but the same percentage is still used, If I add valid_pct(0.1) the percentage is 11% not 10%. Any ideas?
dls = ImageDataLoaders.from_csv(
path=dataset_dir,
folder='train',
test='test',
suff='.jpg',
size=sz,
bs=bs,
item_tfms=item_tfms,
batch_tfms=batch_tfms
)
train_len = len(dls.train_ds)
val_len = len(dls.valid_ds)
test_len = len(os.listdir(test_dir))
val_pct = round((val_len/train_len * 100))
print(f'Amount of images in each dataset\nTotal: { (train_len + val_len) + test_len }.\n')
print(f'Train: {train_len}\nValidation: {val_len} ({val_pct}% of train) \nTest: {test_len}')