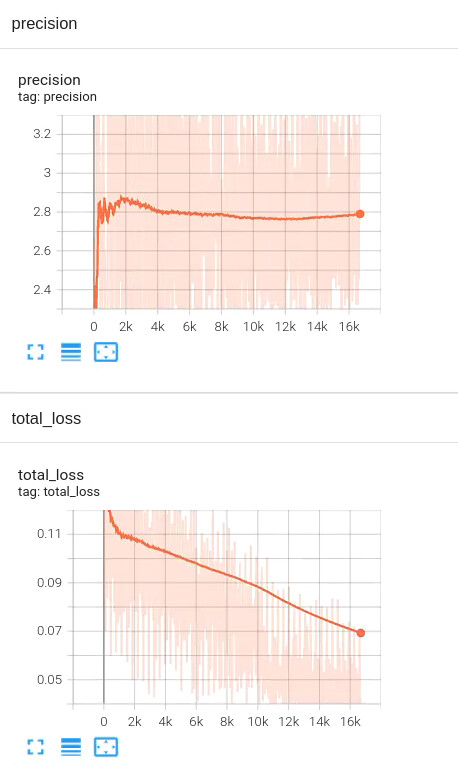
I used the convolutional neural network to do the regression task, input the gray single-channel image and output the single-channel per-pixel predicted value of the same size. The evaluation index of the model is pixel by pixel comparison with the truth value. If the error is less than 5, the score is 1; if the error is more than 20, the score is 0; the score is distributed linearly between 0 and 1 when error is between 5 and 20. The network adopts UNet, loss is simple L1_Loss, and there are three types of data (truth value distribution is different). During training, the truth value is normalized ((X-min)/(max-min)), and the network output is also limited to 0~1. When calculating evaluation indicators, the network output is reverse-normalized (X *(max-min)+min). One kind of data is distributed in the range of 40~80, and the network effect is good (as long as the error is less than 20 points, the truth distribution range is small, the score is relatively easy), and the average score of a graph can be 98 points (percent system). The truth value range of the second type of data is larger (240~750), and the network can only get about 40 points as before. The truth value range of the third type of data is the largest (200~2500), and the network can only get about 4 points. Loss is also decreasing in the latter two types of data, but the score is basically unchanged. Other types of loss(MSE, SSIM, etc.) are also changed, and there is basically no improvement. Although the data with a large distribution range is more difficult, the score seems to be a little too low, may I ask you what is the problem and what is the solution? An image of score and loss during training is attached.