Thanks for this summary!
Regarding point 3.a:
use lr_find() before fit_one_cycle() to get best suited learning rate for underlying data.
I thought the LR finding occurs after the first fit_one_cycle:
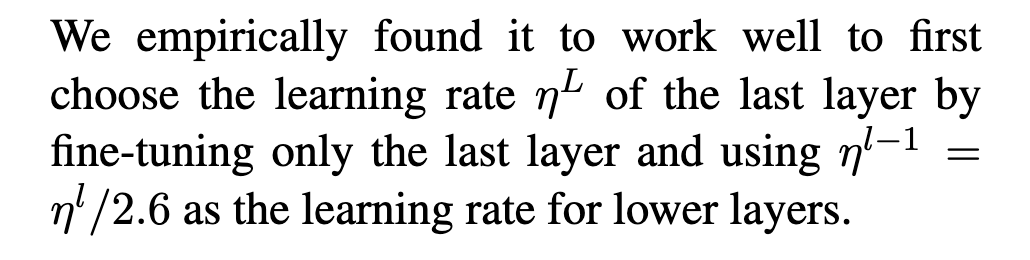
Source: Universal Language Model Fine-tuning for Text Classification