>>> x = t.randn(512)
>>> w = t.randn(512, 500000)
>>> (x @ w).var()
tensor(513.9548)
it makes sense that the variance is close to 512 because each one of 500000, is a dot product of a 512 vector and a 512 vector, that is sampled from a distribution with a standard deviation of 1 and mean of 0
However, I wanted the variance to go down to 1, and consequently the std to be 1 since standard deviation is square root of variance, where 1 is the variance.
To do this I tried the below
>>> x = t.randn(512)
>>> w = t.randn(512, 500000) * (1/512)
>>> (x @ w).var()
tensor(0.0021)
However the variance is actually now 512 / 512 / 512 instead of 512/ 512
In order to do this correctly, I needed to try
>>> x = t.randn(512)
>>> w = t.randn(512, 500000) * (1 / (512 ** .5))
>>> (x @ w).var()
tensor(1.0216)
Ah, yes, so if I understood correctly, if we want to scale the variance of something by a scaler a(which for us we want 1/n), we should do so by a ** .5 which is (1/n) ** .5, because a inside our variance function acts really as multiplying the variance of X by a ** 2. This would mean that (a ** .5) would act as just multiplying by a when we multiply it to our X
meaning
Var(((1/n) ** .5) * X) really is just 1/n * Var(X)
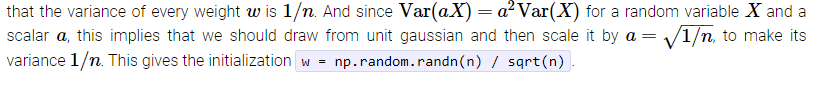
 although I should really be the grateful one!
although I should really be the grateful one!