Hi everyone, I’m new here and first of all I would like to thank Jeremy and all the community of Fastai for helping me that much in these times in learning DL for my master thesis.
I’m finishing my master in physics and this is the first time I actually program some machine learning algorithms, so probably I still do some stupid errors.
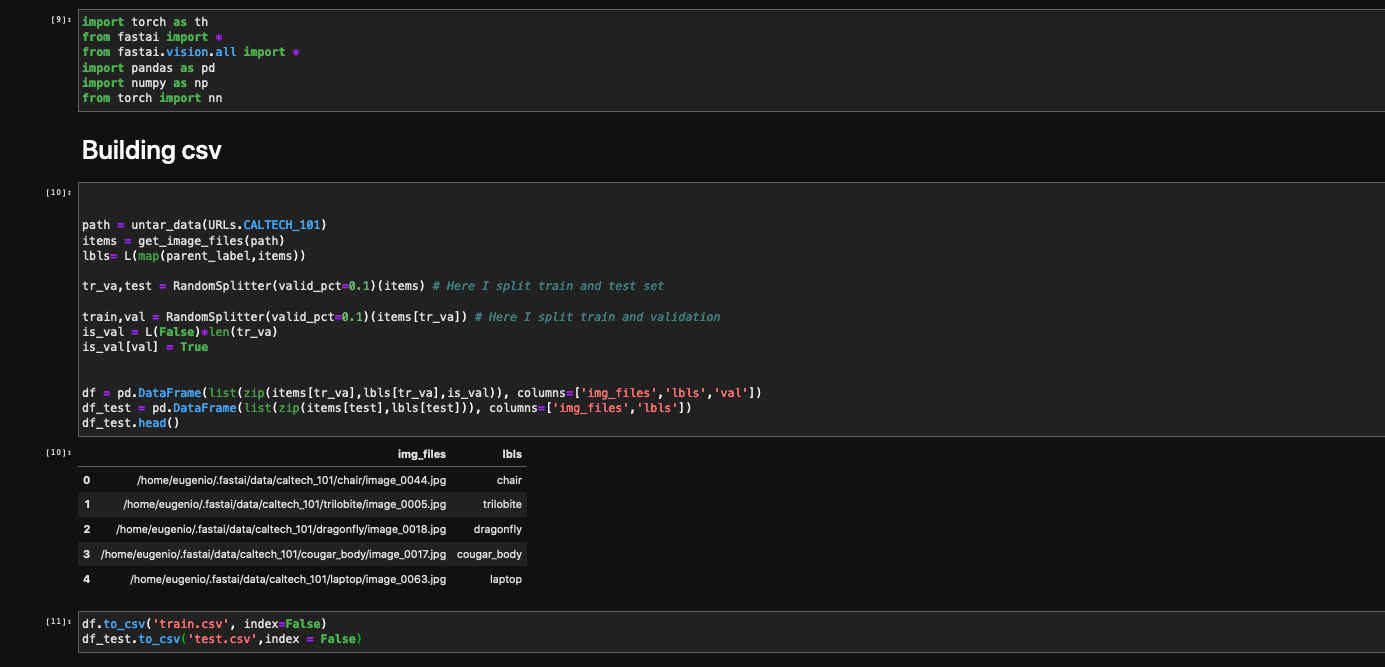
Jumping to the problem, I’m building a simple classifier and training it on Caltech101, so I downloaded the file form URLs.CALTECH101and I subdivided it into 2 csv files that will be my train and validation sets from the test set using a classical RandomSplitter.
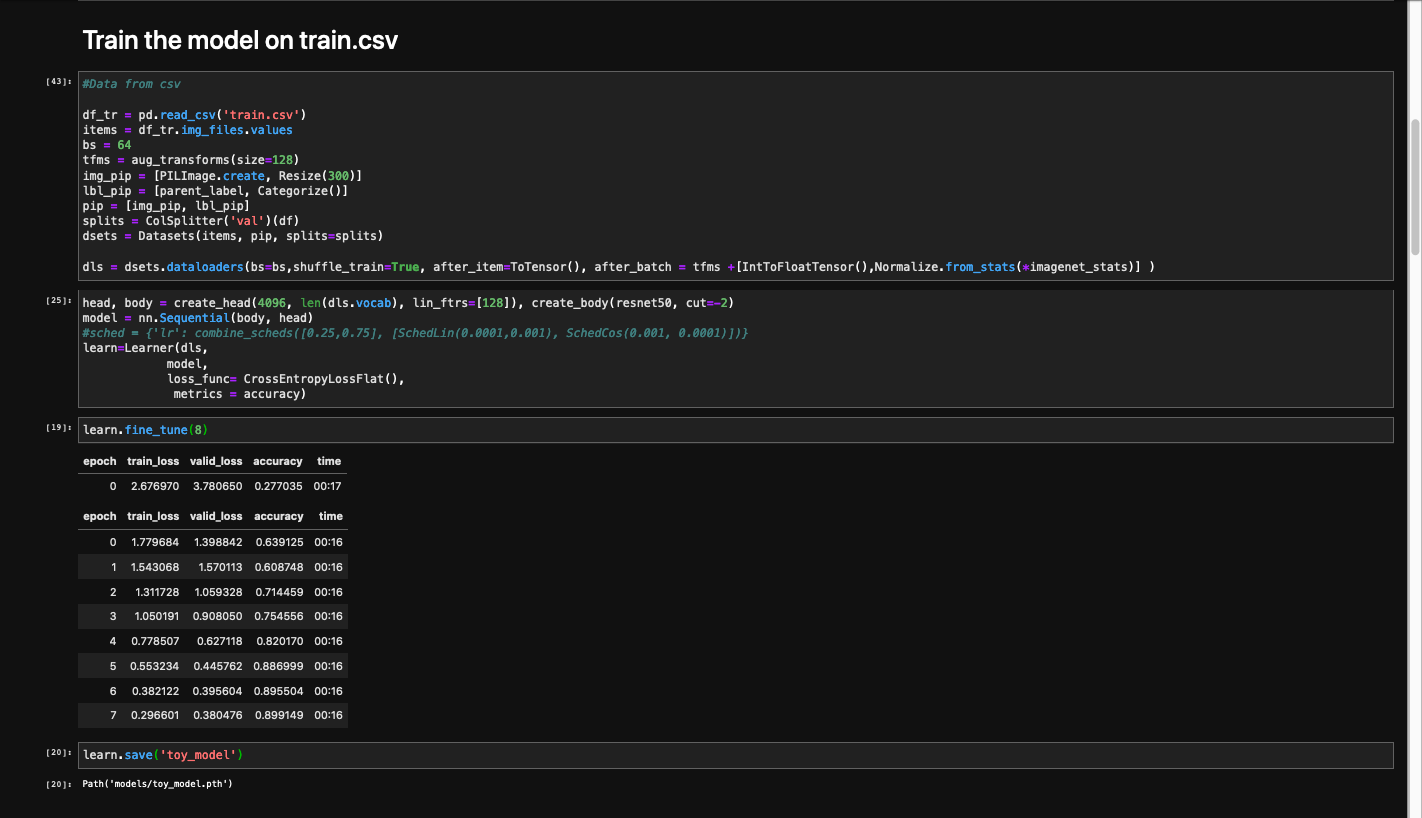
After 8 epochs of traing and an accuracy of almost 90 % on the last iteration, I saved the model.
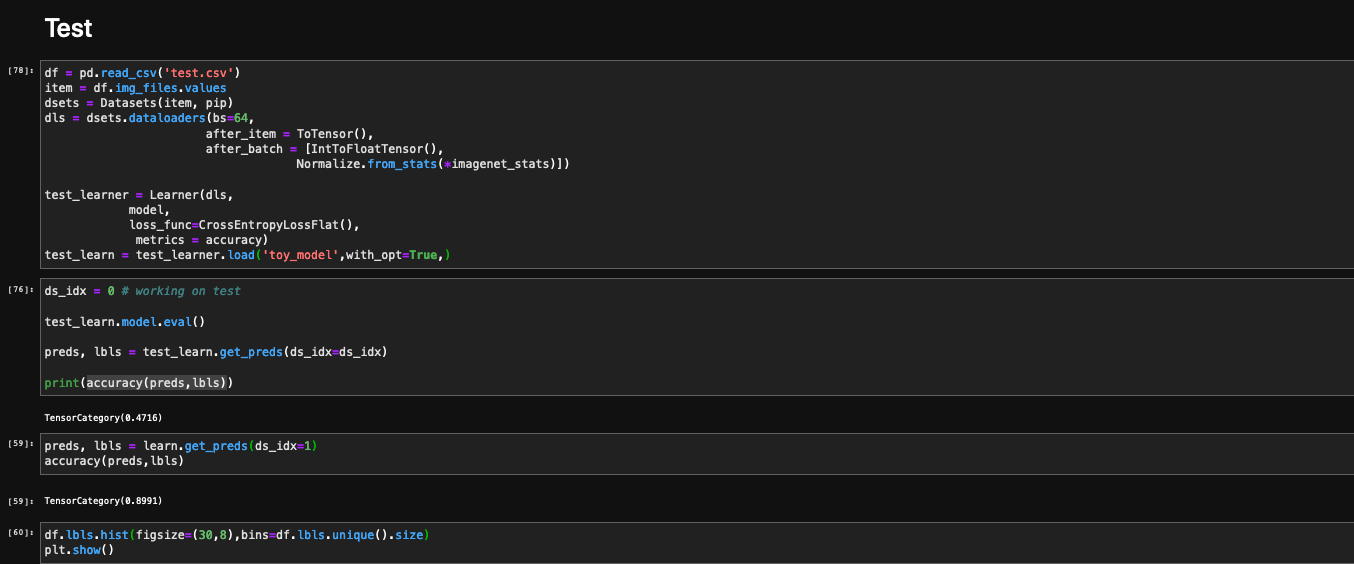
Then I created a new learner using the data in the test csv and i loaded the model again to get the prediction. The problem is when I do that I obtain an accuracy of less than 50%.
I used a very simple and linear code that I will leave her in the hope that someone can help me understand better what do I do wrong
Welcome to the fastai community!
Can you try to do learn.export() and then learn=load_learner() instead of saving your model? Then do inference with:
test_dl = learn.dls.test_dl(test_data, with_labels = True)
preds = learn.get_preds(dl = test_dl)
My guess is that the way you’re constructing new learner may not be consistent with the one you originally trained… or maybe something wrong with the test/train split.
Each learner comes with a set of transforms, such as mapping from class names to integers (vocab), normalization, resizing etc. When you export the learner, you save all those transforms as well, so this ensures that you use the same transforms in training and inference. If you save the model, you only save the weights - so when you create a new learner, it may have a different set of transforms. One thing you could do is compare the vocab between the old and new learner in your original example and see if they are the same (dls.vocab).