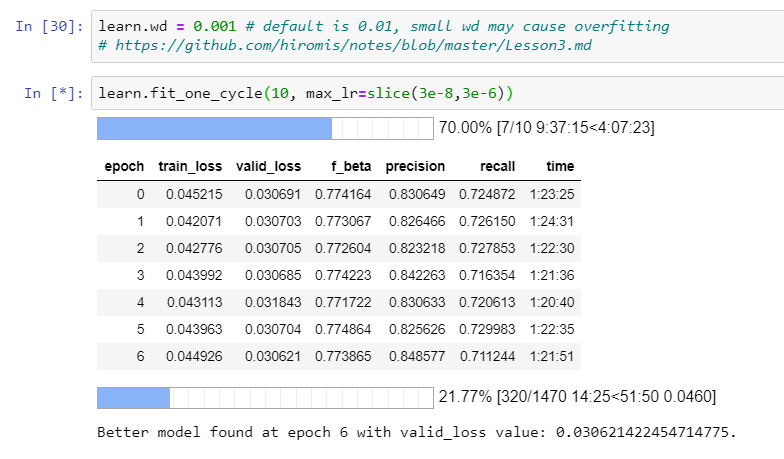
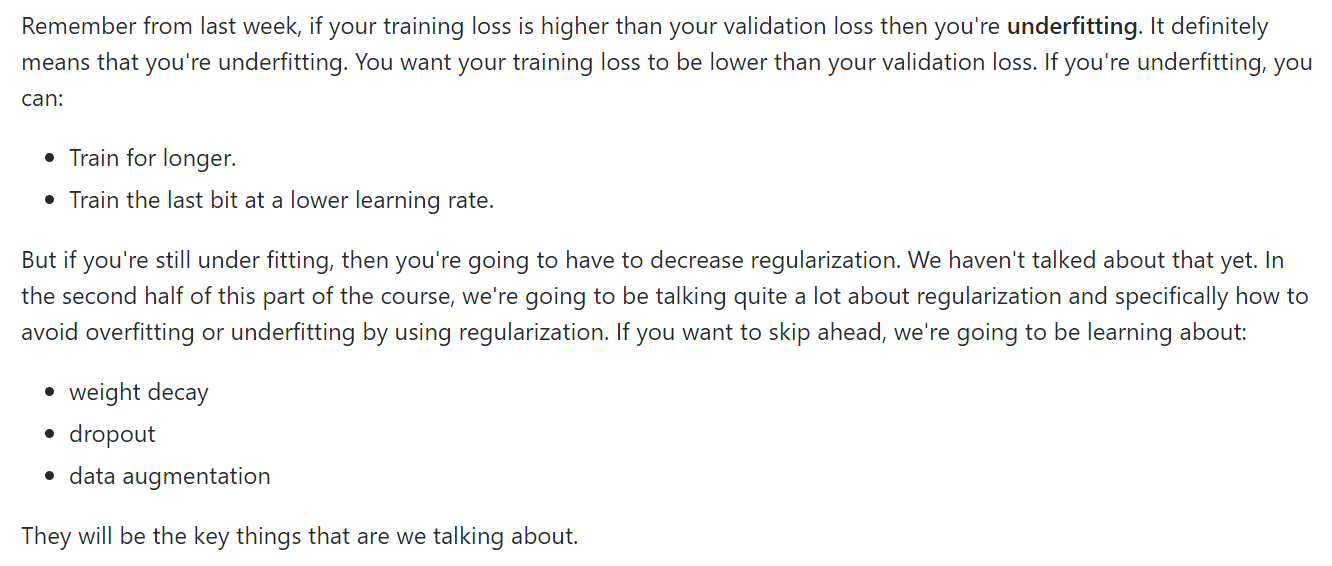
I am training a resNet50 binary classification model with a very big training set (~400k images, 20% of which are used for validation). The two classes are imbalanced, the minority class ~7% of the examples. My problem is that I would like recall to be higher and that I have some hopes since I still observe under-fitting (i.e. training loss is higher than validation loss). However, both losses are very close to zero. See picture below:
Am I done training or is there something else I can do to improve recall? I trained for long with low learning rate already, I also decreased weight decay… but I do not see a way to load a learner (aka learn.load()) and then modify data augmentation or dropout. Can somebody help with it?
My losses are currently so low that I am not quite sure whereas it makes sense to continue training but I would like to have higher recall. Should I maybe try to train with a balanced data set?
Hi you can definitely do both. I can post some sample code to do it when I get back to my computer, or if you want to post your notebook I can post detailed directions.
My recommendation is to increase augmentation. If you are not using mixup or cutmix or similar thats what should improve your results here.
Thus oosting your notebook would be helpful to see what you are already doing.
Ill post more when I get back.
You will find model weights in models/ directory with .pth extension.
you can add transformations with
tfms = get_transforms(do_flip=True, flip_vert=False, max_rotate=180.0, max_zoom=1.2, max_warp=0.0, max_lighting=.3,)
# you should try changing these values according to what works best for your data.
and you can add new data to the learner as
src = (
ImageList.from_df(train_df,PATH,folder='train',suffix='.jpg')
.split_by_rand_pct(0.2, seed=42)
.label_from_df(cols='classes')
)
data = (
src.transform(tfms=tfms,size=299)
.databunch(bs=bs)
.normalize(imagenet_stats)
)
learn.data=data
learn.load('/models/bestmodel')
#path to your weights without.pth extension
train longer now
Not really required. Jeremy says he never tries to balance the data.
Thanks a lot for the replies! @LessW2020 I unfortunately cannot share the notebook (work related…) but great ideas. I am using data augmentation but only very little since the images are from a sensor production line so they are always taken in the same way… hence certain changes of light, angle, etc do not really make sense. I am training with 224*224 using mixup and mix precision training. I had never heard about cutmix? Would you mind sharing the fastai link to it.
Thanks a lot @PoonamV for the code snipped. How can I modify dropout? As said, I do not believe data augmentation will help that much. I will try label smoothing! I did not new about this trick either. Any good source where I can read / watch more about it? Why do you think stratified k-fold should help? I understand the technique as a way of getting more reliable estimates of the training / val loss / metrics… but not much else. What I am missing?