While going through v3 of the course, I’ve been looking at the Microsoft Malware Detection Kaggle competition. The dataset is tabular and involves primarily categorical data.
Some columns have literally millions of examples of one value, with hundreds of another. For example, for the boolean column AutoSampleOptIn we have 8,921,225 examples of True and only 258 examples where it is False. For this reason I don’t expect to get much predictive value out of this column and feel like I should drop it from my training/test sets.
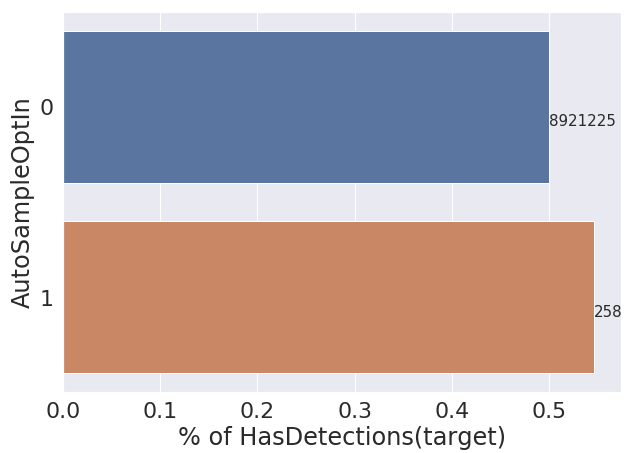
Is there a rule of thumb or guidelines that suggest when I should drop a feature like this?