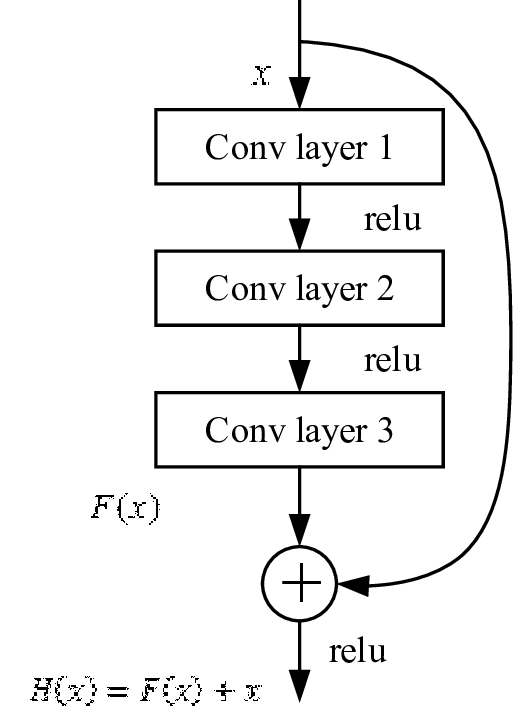
So here is a picture of resnet residual block:
As I understand it, we just take the current features, pass them through several conv layers to find more complex features. And then just sum the original features and new more complex features??? Shouldn’t they be different enough so that a simple 1 + 1 addition will make everything messy? Why does this even work?
There are at least two ideas:
- By adding skip connections, you allow gradients to flow easily from layer to layer. This helps to train really deep networks - from the very start, even the lowest layer receives activations from the top layer!
- Imagine the conv-layer block in fact does nothing (it is an identity function). Then together skip-connection and the conv-block do nothing (neither make the result worse or better), right? But you train the conv-layer block with backpropagation, so it must do something to minimize your loss. Then it doesn’t make anything messy, because each lower layer takes the skip-connection signal into account when updating the weights.
It is not really 1+1. It is about do you want var1+var2+var3 for understand the color of paper. At that time, you only need small amount of var is good enough to understand the feature of a paper. But if you try to use var1+var2+var3 very complicated model with many of “var” to understand the paper, your model will start to understand too much about certian paper, and it will fail in unseen paper. That is why you need var1 +skip|+var2+var3|= var1, and var1 is good enough.
@noisefield
@JonathanSum
So intermediate convolutions don’t really learn more complex features on they own, but instead forced to generate some useful noise with reference to skip-connection signal?
This is like RNN that propagate signal with some modifications?
Sure they learn useful features, how would they work otherwise  only on each layer, they generate features based on input from both the previous layer as well as other preceding layers.
only on each layer, they generate features based on input from both the previous layer as well as other preceding layers.
I would not compare it with RNN, because in RNN therr are usually no skip-connections between layers. In Transformers, on the other hand, skip-connections are used, again, to be able to train deeper networks.
I think you are saying LSTM or GRN because they are their forget gate.