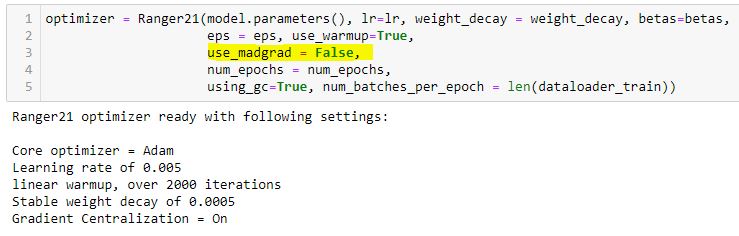
I’ve seen discussions on this forums about ranger, SAM, gradient centralization. I was wondering if there was a consensus on what works well today for fine tuning a network for things like kaggle competitions.
The fastai default is still Adam with One Cycle schedule. And that’s what I use most of the time, but maybe I’m missing out on some new hotness?
In my case, it is usually RMSProp with One Cycle. Adam, for some reason (maybe due to the nature of my problems, maybe it just sucks), never gives me decent result, but RMSProp has been quite reliable.
Regarding the scheduler, I’ve found flat cos to be more sensitive (to the model, learning rate, etc.) than One Cycle, and the latter converges quicker. However, that is not always true, especially as the number of epochs increases and you become more familiar with flat cos.
I myself haven’t had success with ranger+fit_flat_cos in the few times I tried. But maybe I was using it wrong. Unfortunately the experiments here only show training from scratch.
How do you do it in fine tune. Two times flat+cos for frozen and unfrozen? Or maybe only flat for the frozen portion?
How about learning rates, does it still make sense to use lr/100 for the earlier layers like fine_tune does?
I’m currently completing a rewrite of Ranger (duly named, Ranger21) to use some of the newest innovations that have happened since Ranger was released 1.5 years ago.
Specifically, I have added the following:
1 - Choice of engine - madgrad (dual averaging) or AdamW style for the primary moment calculations
2 - Stable weight decay. Most of the adam variants are arguably various patches to work around the core issue that without normalizing the decay relative to the variance, you are creating a ‘moving target’ for the optimizer…this has been a nice improvement over standard adam style weight decay and AdamW style decay.
3 - Positive negative momentum - adding noise to the optimization helps it to settle into wider minima and thus better generalization. The problem is randomly adding noise will almost certainly result in worse outcomes…the trick is the noise has to be anisotropic and parameter dependent.
Thus, positive negative momentum applies this to create suitable noise and better results in my testing.
4 - Gradient centralization - brought forward because it continues to work well with either engine.
5 - RAdam replaced with linear warmup - based on an earlier paper, RAdam simplifies to a linear warmup for same improvements with much easier calculations.
6 - Cosine decay at end of run - basically fit flat cosine but built into the optimizer directly. Just spec what % to begin the decay (.65 is generally solid start).
Of interest MSFT research did a paper on lr scheduling and found that fit flat cosine (technically they used linear decay as they didn’t see much difference in decay style) worked the best of the different lr schedules. They called it hyperknee, but the schedule is the same regardless of name.
In general for transformers, madgrad is usually a better option and for CNNs, the AdamW style engine is on average better. But that’s only based on my initial testing…
It’s still in ‘alpha’ but if you want to give it a whirl it’s here:
Thank you for the amazing work @LessW2020. Since the learning rate schedule is baked into the optimizer, how do you see we best use this in fastai? Do we just call fit in fastai with the Ranger21 optimizer?
Thanks @kcturgutlu for reporting this issue.
I don’t repro it on my setup, but in reviewing the code, I see where it could occur.
I’ve made a fix that should avoid it, and checked it in.
Could you get the latest update and let me know if that resolves for you?
Thanks!
Hi @dnth,
Thanks for the kind feedback.
To your question - if you want FastAI to control the learning rate or otherwise ensure Ranger21 doesn’t adjust the lr, then you can set the following params to tell Ranger21 not to adjust the lr.
use_warmup = False,
use_warmdown = False
That will override the default lr handling by Ranger21 and return control to you/FastAI.
Hope that helps,
Less
oh - otherwise if you want Ranger21 to handle the lr (recommended) then yes you can just call fit and Ranger will do the warmup and warmdown to the lr directly with no other action needed on your side.
Note that I’m only running in pure Pytorch atm, so there may be other issues I haven’t hit with how latest fastai learner interacts, but assuming the optim wrapper trick works, then just calling fit should do it.
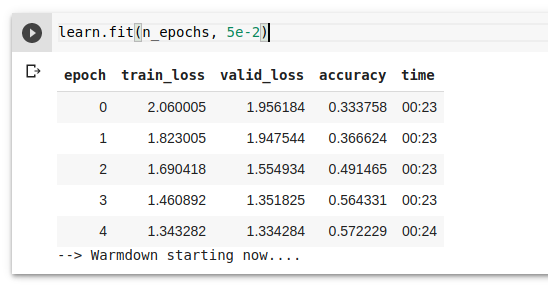
Thanks for posting. Its not going to do well in your setup with those settings.
Why?
It’s showing a default warmup of 2000 iterations… but you are running a total of only 365 iterations total…so it never even ramped anywhere close to the full lr during your short run.
I wouldn’t run less than 10 epochs for testing for reference but the bigger issue here is the default warmup didn’t account for someone running so few iterations.
1 I’ll add a better auto warmup handler tomorrow to check for short runs like this, so thanks for posting.
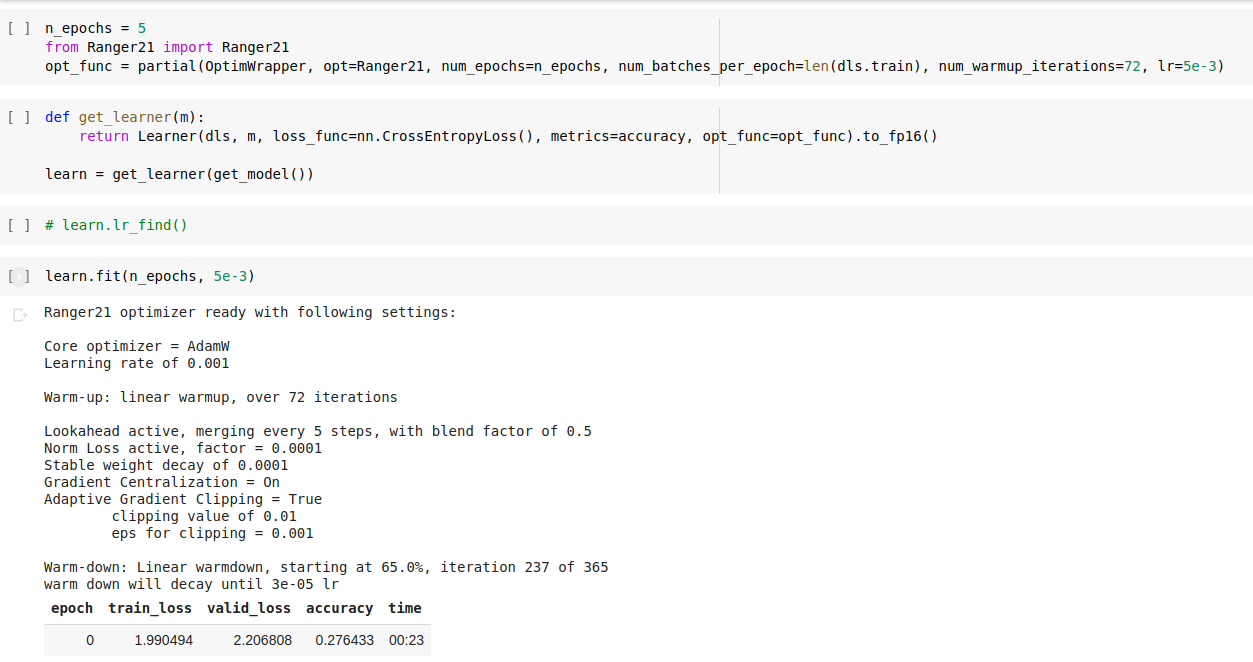
For now set the warmup iterations to 20pct of your total. If 500 iterations then 100 or for 365, then 72.
That way it will cycle through warmup, flat and warmdown, and you’ll get much better results for short runs.
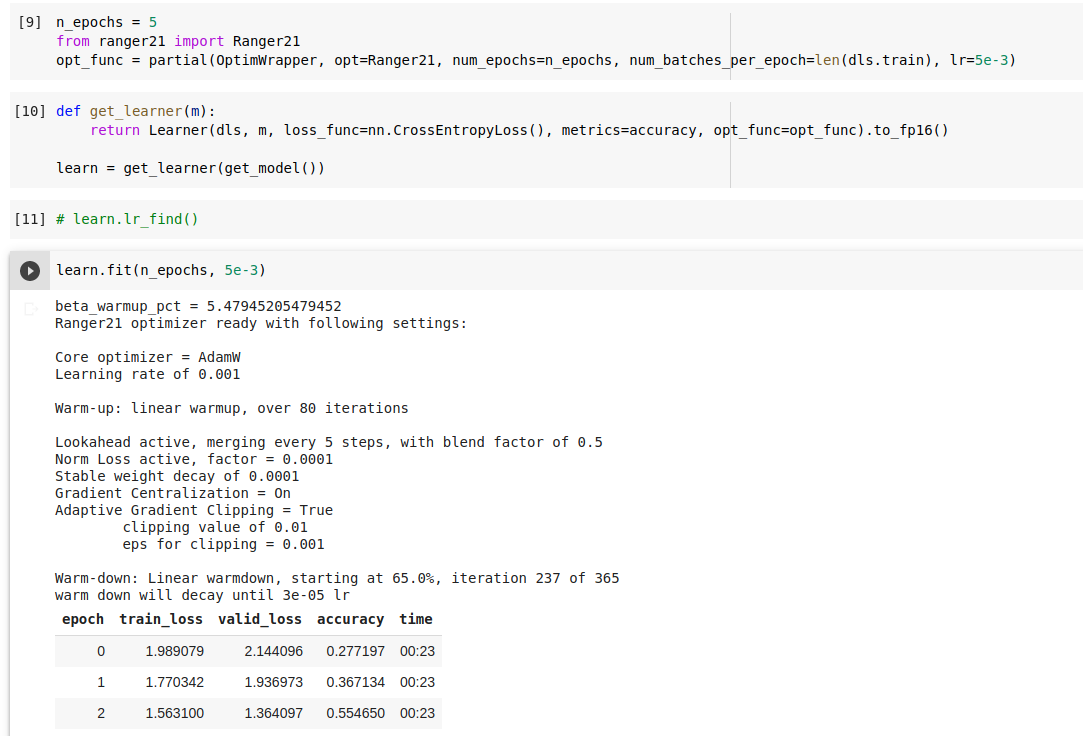
Thanks Less! I got better results with your suggestions. I note one peculiar thing with the learning rate. I passed the lr=5e-3 via optim wrapper, however Ranger21 doesnt seem to use that lr value…
Hi @dnth -
I was able to add in the ‘smarter’ warmup. It will now check the beta2 formula result vs the total epoch times and if it’s over 45% of the total training then will fall back to an auto 30%.
Thanks again for reporting this, didn’t even think about the issue of short runs before.
Re: lr - if you restart your kernel and run does it show the correct lr? I’ve noticed before (last year, haven’t tested lately) in fastai that optimizers can kind of get stuck in memory and not reflect updates, so that’s my initial guess.
I tested quickly in pytorch setup, and checked the code as well and generically any changes will be used, so I think the issue might be fastai holding the optimizer within the wrapper?
Please restart the kernel and confirm that you see the expected lr and that would help confirm that.
Thanks again for the feedback!
Thanks very much for confirming the issue is not on my side @dnth
Also glad to see the pip install worked - trying to make Ranger21 easier to use is something I want to focus on over the next few weeks.
Thank you for your hard work in making the state-of-the-art accessible to everyone in fastai/deep learning community. Personally, your contributions (this, and all your other writeups/blog posts) had accelerated my learning progress and research significantly. Thanks again Less!