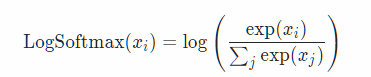Could you be more precise as to what you don’t understand ?
If you don’t understand the math of the function I’d suggest to go back to Jeremy’s lessons where he explains softmax.
If you don’t understand how’s the math is translated into code (because of the tensor operations maybe?) I’d suggest to set a sample x = torch.randn(...,...) to experiment with, and then apply the different functions successively to understand what they are doing. You can also look them up in PyTorch documentation.
Please let us know what you understand or if you still have questions, it will certainly help others too
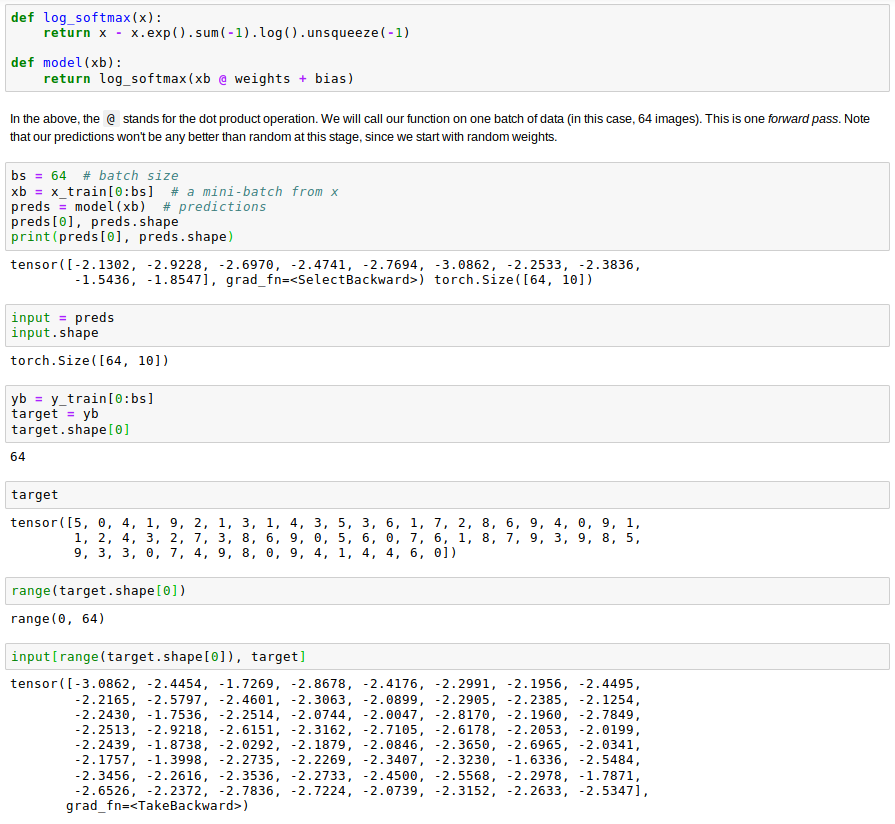
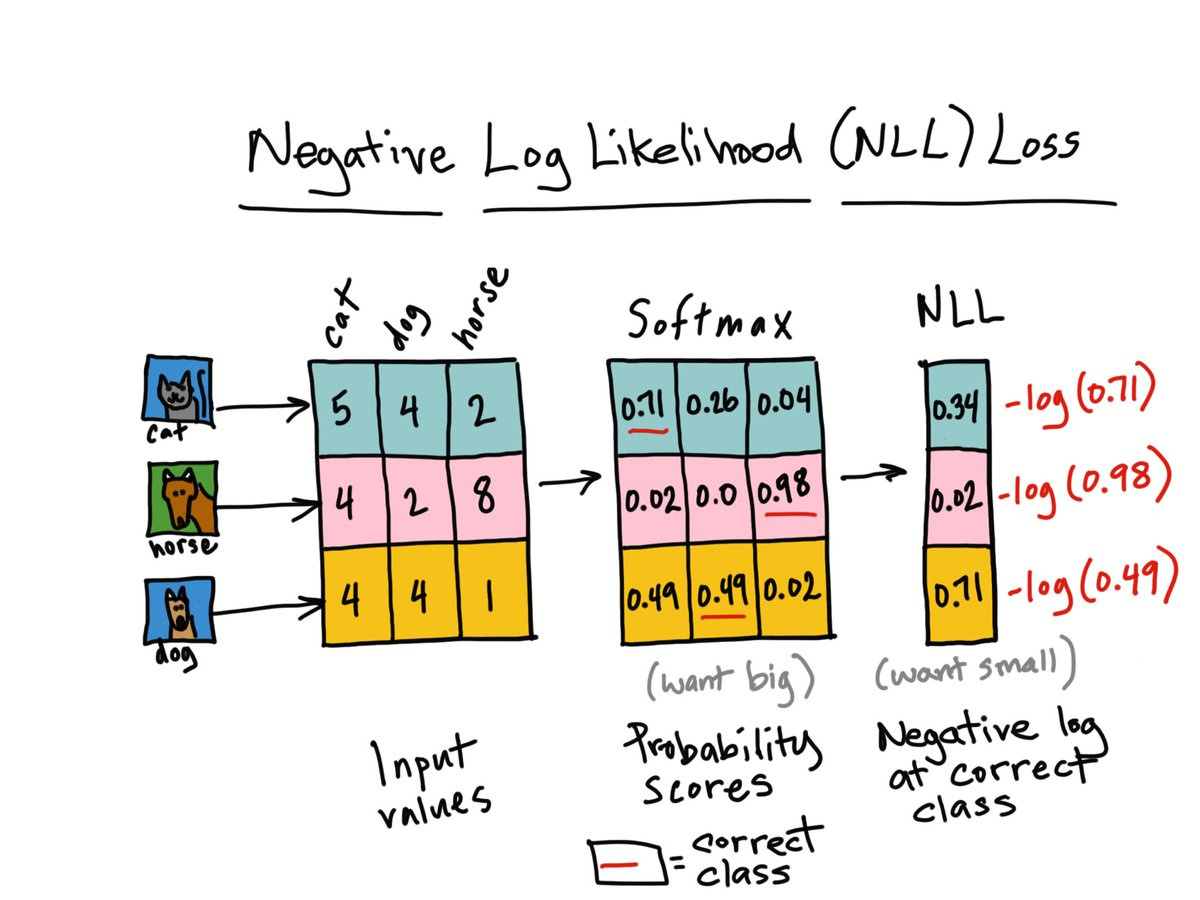
I was reading that today too. That negative loss-likelihood is kinda weird, with the slicing [range(target.shape[0]), target]. I should find the time to run the code. Will update if I figure what what it’s slicing
When I run the training loop in the “Neural net from scratch” part of the notebook, I print the loss after every batch. The loss is not getting smaller during the loop and also the accuracy ends up being 1. I dont get why this happens. Does this mean I get 100% training accuracy(overfitting) with just 1 neuron? And shouldn’t the loss be dropping during training?
The loss should get smaller while running the training loop, as long as you did not change anything in the given kernel. However, it is pretty hard for the network to train with such a rough weights update policy : the model is kind of oscillating around the optimum you are trying to reach. That is why researchers have developed more sophisticated methods for weights updating.
Here, you have 10 neurons : one for each digit.
If you run the notebook, you get 100% accuracy after a couple of epochs. Actually, the kernel evaluate the accuracy on the last trained batch :