@sgugger I did the test you suggested previously.
- Baseline: no gradient accumulation
- Gradient Accumulation: batch size divided by 10, update every 10 batches, learning rate divided by 10
- Training loop: regular
fit(nofit_one_cyclefor now to avoid potential issues with scheduler) - 5 runs for baseline + 5 runs for gradient accumulation (we show mean and min/max for each group)
Results are consistently worse in the gradient accumulation variant (blue are the runs with and orange is the baseline).
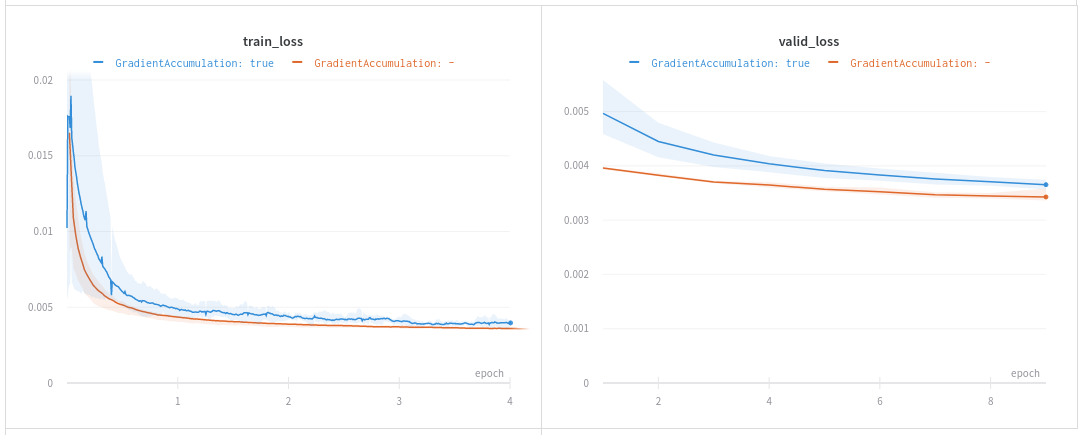
As you can see, learning rate is fixed and has been divided by 10 while other optimizer parameters are the same.

When looking at gradients, they are about 10 times higher with GradientAccumulation (as expected) and weight parameters remain pretty much the same.
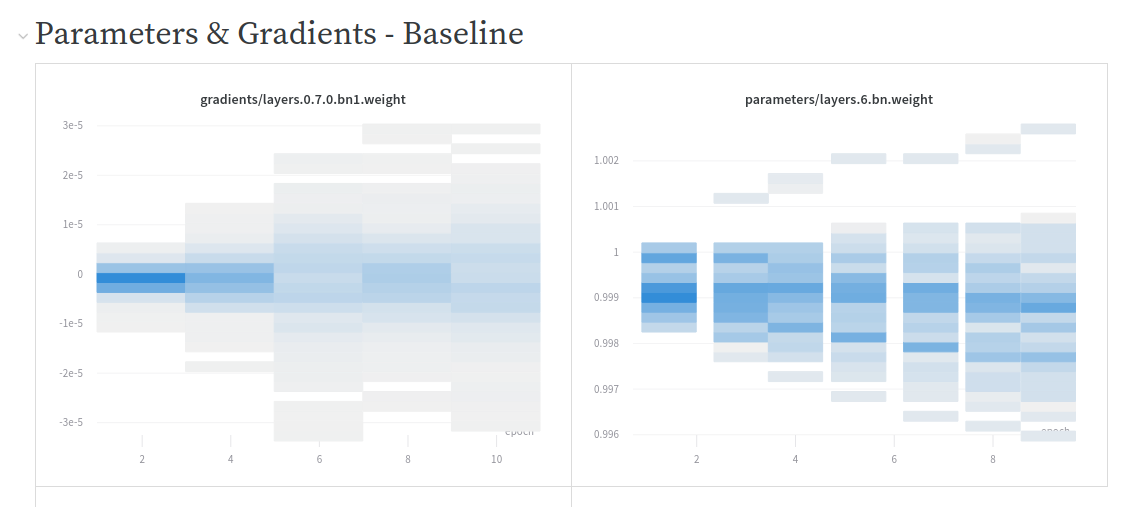
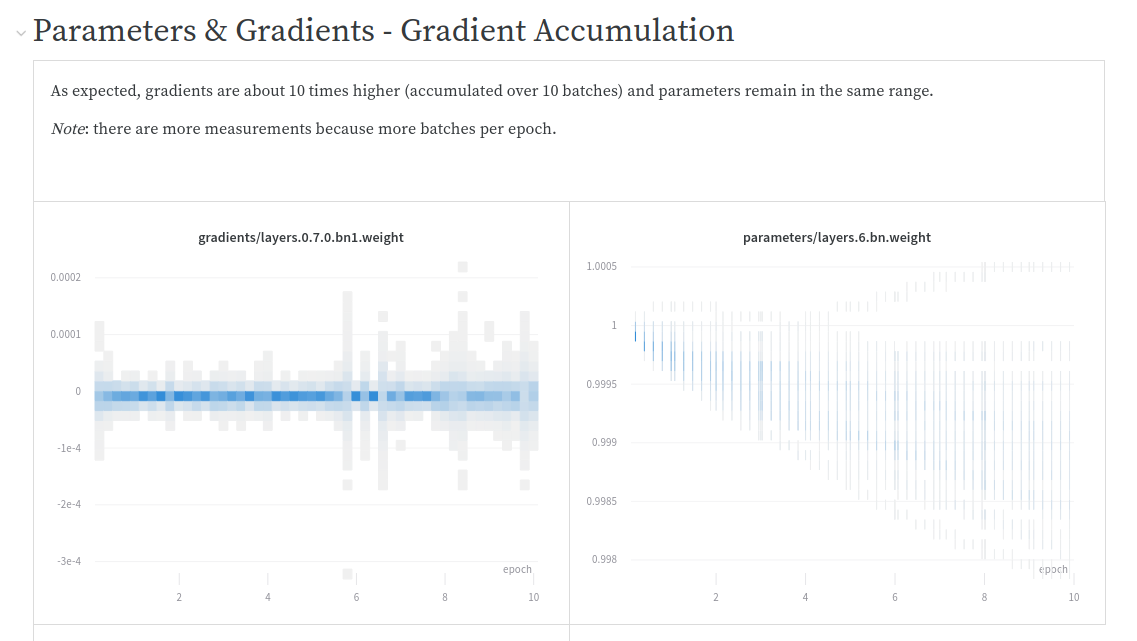
You can see the full results comparison here.
Do you have any idea of an other parameter I should adjust when doing gradient accumulation?
I was thinking it could be due to the weight decay but it is not called until all gradients have been accumulated…
Note: I’m going to propose a PR to WandbCallback which I modified so it now logs automatically some config parameters to help me make these graphs.