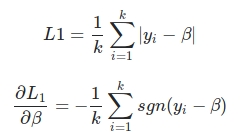Thanks for the response
I think I used the wrong terminology - when we say “accuracy,” we automatically think of the metrics we print out. I do understand that if we used accuracy 0/1 over a validation set, it will not work. But I was thinking of a situation where the output of a model is a continuous variable (say, sales of a store this month).
If a model said $3,000 and the target is $5,000, then one could say “It is 60% accurate”. So I was thinking of something like this for a minibatch of size 1:
Well, radek explained it much better than I could, but I will try to expand it a bit if I can
First, the absolute value function is not differentiable at zero, so you have a problem there (edit: i don’t know if it’s really a problem, it’s basically what you have in an l1 loss, you could use the sign in the derivative). But suppose you took the square instead of the absolute value, well then you have to see how you define \hat y, because your network will output real value numbers, and you have to decide which of those number you take as your actual prediction, for example by taking a max of those numbers, which is another non differentiable function. I think you can “fix” this by doing some hacks like dividing by cases (like it’s done with relu), but in a regression setting, a loss function that cannot traverse the whole (positive) real line is not a very good loss function.
You’re right. I have a vague recollection of this from school. Is this the reason why we square then do square root (even though it feels like you’ll just come back to where you started with negative sign removed)?
** UPDATE **
I think I had a moment. This will become problem when y = 0. And what I am trying to create is starting to look more and more like RMSE by trying to fix all those issues.
Is there a chance to look into Hinton’s Capsule Networks?
Also, a deep dive in designing good reward function for Deep Reinforcement Learning would be awesome. Specifically, RL agents learn what they try to optimize, but when looking at data and Ai ethics, how can one ensure not to codify unwanted higher order effects. How can we even measure that?
After posting that I started thinking (and edited afterwards) and while it’s true that it’s not differentiable, you can use the sign to separate both cases when you are taking the derivative (image attached below), so it’s doable, it’s basically an l1 loss function. But I think you still have a problem with the \hat y, because thresholding on that conditions the values your loss function can take.
I think there are several reasons why you square and then take the root, but I haven’t thought it deeply so I may be wrong (note that when you do that, you take the square root of the sum of the squares. In the equation you wrote, the square and the root cancel each other, which does not happen for example when you do RMSE). One reason I can think of is because it’s really differentiable, another reason is because when you, for example, square the difference between predicted and actual, you penalize more heavily the errors than you do with absolute value, but then you can have the problem that all those squares added up amount to a very large error, so you “bring it down” to a more reasonable value by taking the square. It’s not clear to me now when you would want to do that, and when you would want to do just MSE. I think it’s an interesting topic to touch in the lectures.
I always had a problem reading probability formulas in papers, they perhaps mean something simple, but looks very intimidating. It will be great if you can give insights on how interpret them and how not to sweat about it.
When Jeremy was showing “why sqrt5” notebook and conducted a few experiments with numbers, he used gut feeling and common sense to realize whether sth is concerning or not (I.e his version of init vs pytorch’s).
I often heard about statistical significance of experiments and as opposite p-hacking. What is that and whether Jeremy uses p-values in doing research?
How explicit do you need to be about what operations get executed on the GPU?
Do you need to explicitly tell pytorch to use the GPU?
If so, how do you decide when to do so?
How do you know whether a given operation is happening on the GPU or not?
Not sure if it fits with what you’re getting at, but I am very hand-wavy on GPU execution generally, especially when you have to specifically send something to the GPU in pytorch and when you don’t. I assume that pytorch “magically” executes things on the GPU wherever possible, but I also see explicit device='cuda' calls, so I’m not sure when you need to make that call.
I also strongly suspect that this could be answered by a source dive plus documentation read, and might not be the kind of “fundamentals” you’re getting at.
Edit: Yep, a documentation read and a source dive cleared it up. this pytorch documentation page is very informative and particularly makes it clear that a tensor gets loaded to a device, and by default any tensors that result from an operation on that tensor will stay on the same device. Then, fastai’s torch.core library tries to use the GPU by default . So, most of what happens will happen on the GPU, if there is one, and unless you say otherwise.
I’m sure there must be edge cases where you’d need to manually specify and I’m still curious to find out what those are, but consider this question answered
You also want the function to give good gradient juice in the right places.
For example, in Focal Loss for Dense Object Detection [0] they come up with a function that focuses on classes that are under represented.
One more vote for more detailed explanation on how to create a custom callback. What are the pieces we have to build, step by step, as though we don’t know much. What are the special things we have to do if we want to build a callback that descends from LearnerCallback, where we have to pass the “learn” object when we instantiated it. Once we understand callbacks, there are no limits to what we can do with the fastai library.
The majority of the time we just concentrate in the datasets already there.
I would like to see the best to tackle a problem from scratch and see the best way to handle the data engineering and then creation of the model.
Cross entropy, by the way, has a really fun intuition
Given an event that has probability p, information theory says (not sure I can come up with a better justification) that it’s interesting to look at the quantity
\log 1/p = - \log p
I think the \log 1/p version is easier to think about, but you’ll see -\log p more often. There are various names for this thing, but the one I like the most is to call it the “surprise” of the event. Here’s a nice post that covers the idea in more depth, but the name makes some sense: if an event has probability 1, then its surprise is \log 1/1 = 0, which seems about right; and as the event gets less and less likely (that is, as p goes to zero), the surprise gets bigger and bigger. And finally, it has the nice property that if you have two independent events with probilities p_1 and p_2, then their joint surprise works out to be just the sum of their individual surprises: \log 1/p_1 + \log 1/p_2. This works because the joint probability of two independent events is the product of their probabilities, p_1 p_2, and \log turns products into sums.
At any rate, with this interpretation, the cross entropy loss measures how surprised your model is by the training set, on average As you train your model, you’re tweaking it so that it finds the training data less and less surprising.
More generally, anywhere you see a “negative log likelihood”, you can think of it as a surprise if you like.
This surprise concept is useful in other places too. For example, the KL divergence from one probability distribution p to another probability distribution q measures the “excess” surprise you would feel, on average, if you thought q was the right distribution for whatever you’re studying—when whoops, actually p is.

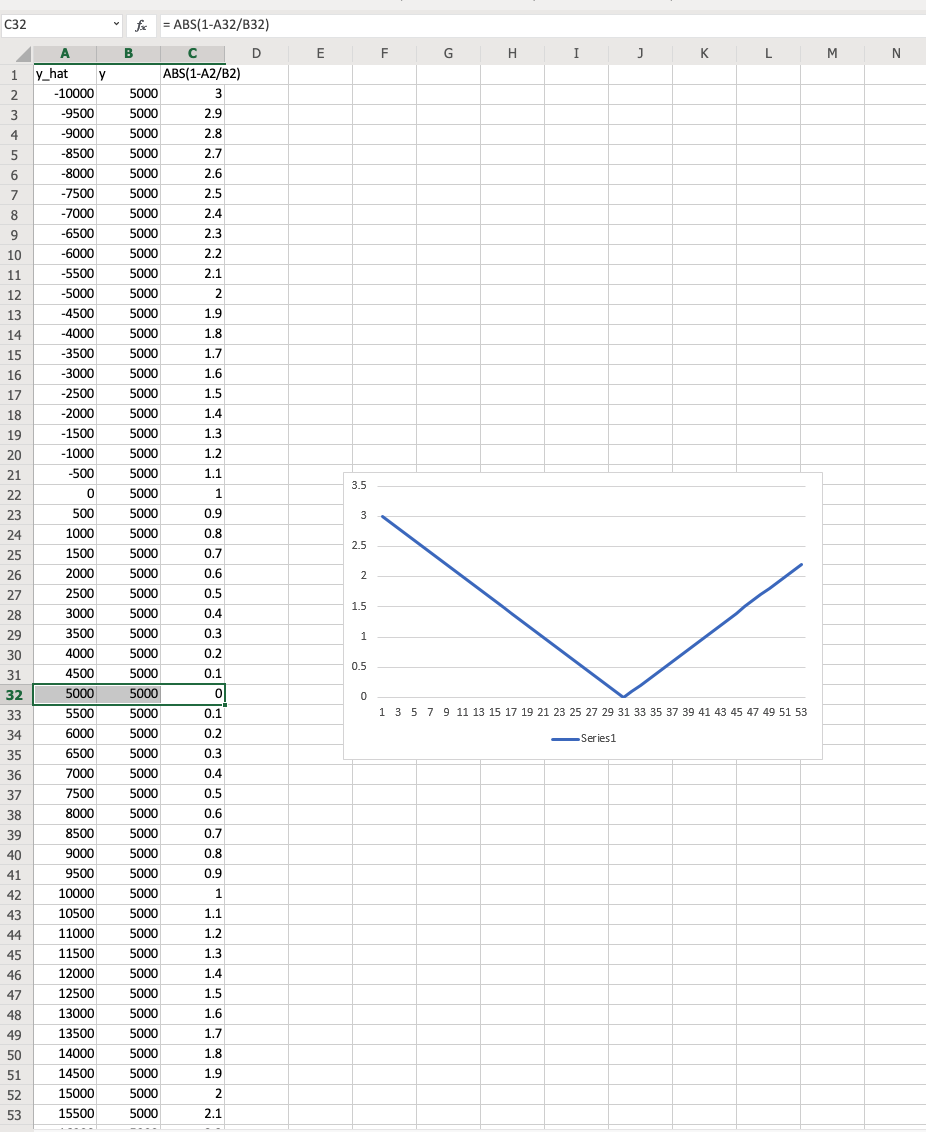


 moment. This will become problem when y = 0. And what I am trying to create is starting to look more and more like RMSE by trying to fix all those issues.
moment. This will become problem when y = 0. And what I am trying to create is starting to look more and more like RMSE by trying to fix all those issues.