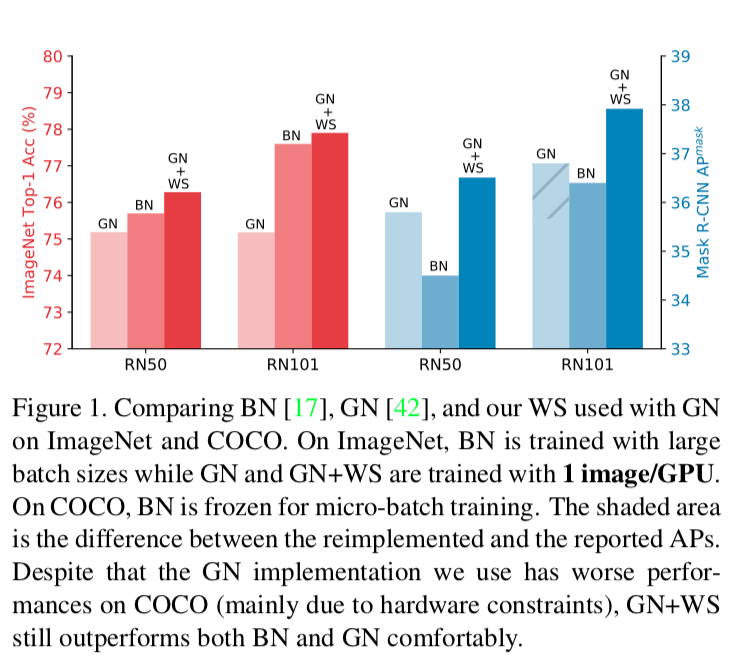
Yes, there’s a recent paper on arxiv: Weight Standardization (WS) that shed’s light on this topic. Below is a screen shot from the paper comparing the performance of their network initialized with weight standardization (plus group normalization) with batch size=1 compared to network trained with BN with large batch size.