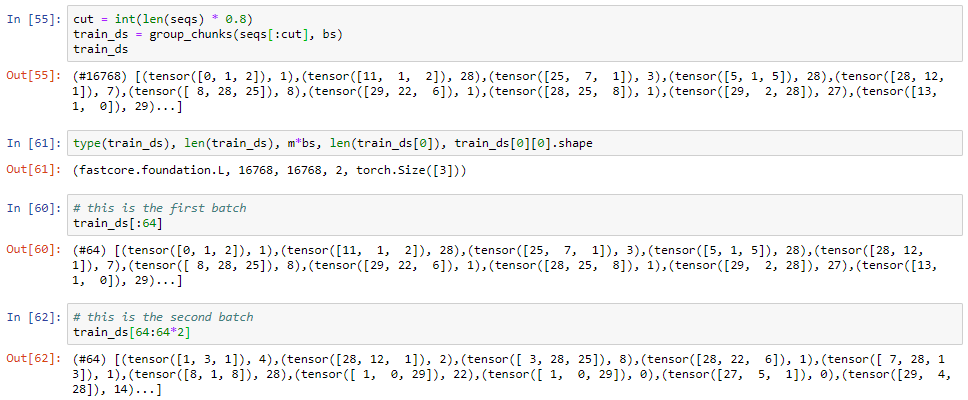
I was going through chapter 12 of fastbook. In the section Mataining the state of RNN a concept of BPTT is introduced which helps our model to keep track of previous data in our current batch. Following a new method is suggested to generate our dataset. It is said that the data we have should have following the sequence:
The first batch will be composed of the samples:
(0, m, 2*m, ..., (bs-1)*m)
then the second batch of the samples:
(1, m+1, 2*m+1, ..., (bs-1)*m+1)
For this to be achieved a function group_chunks is introduced:
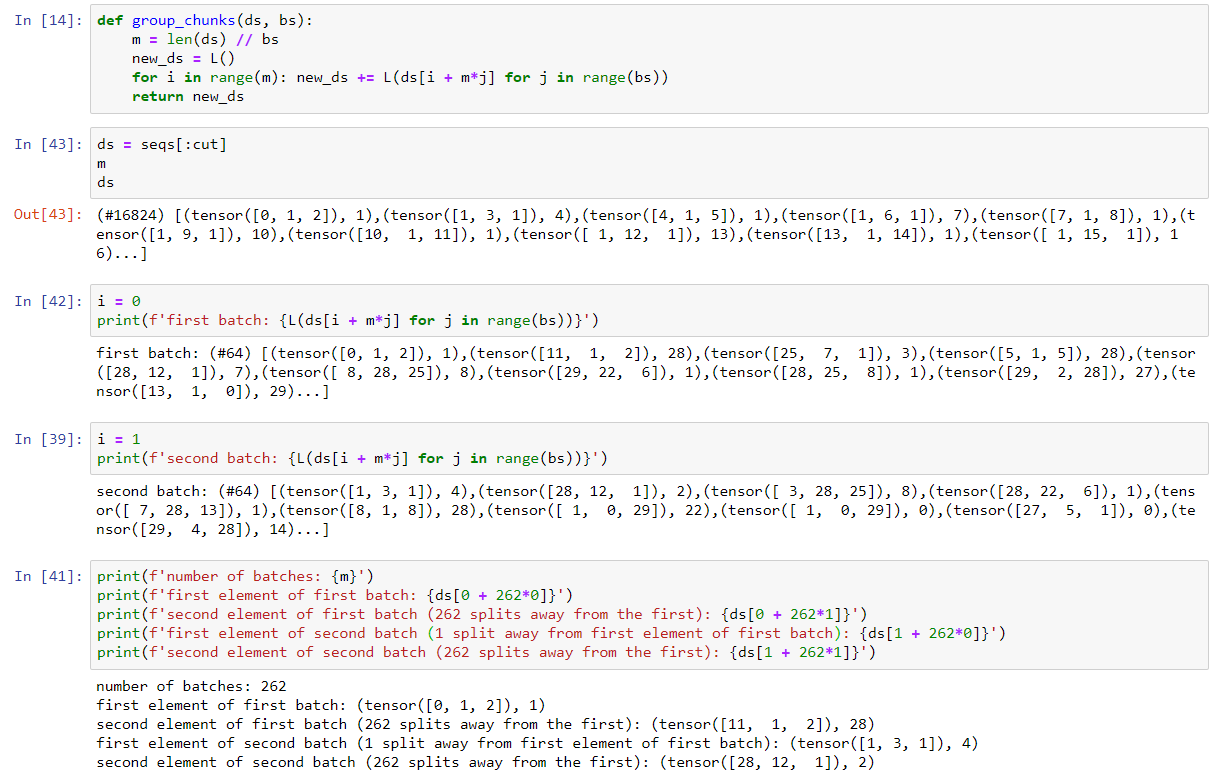
def group_chunks(ds, bs):
m = len(ds) // bs
new_ds = L()
for i in range(m): new_ds += L(ds[i + m*j] for j in range(bs))
return new_ds
Why is this function used? What is the purpose of this function?
the DataLoaders.from_dsets function takes two datasest, which are nothing else than iterables of tuples. group_chunks is in charge of creating those datasets.
Itself, it is fed a dataset (the unshuffled list of all the tokens in the corpus) and chops it in chunks of tokens keeping a meaningful order. See below for more clarity:
I know it can be counterintuitive, but this is actually not shuffled. It is exactly in the order it should be. One element after the other, row wise batch after batch (NOT in the same batch).
Think about it. All elements in one batch are processed at the same time, not one after the other in sequence. Therefore if the first element of the first batch is 0, the second element of the first batch does not necessarily need to be 1. It is m in our case.
Given we are keeping the state of the RNN, though, what is actually crucial is that the second batch aligns with the first. So the first element of the second batch must follow consecutively the first element of the first batch. Infact, it is 1 (following 0). The second element of the second batch (m+1) must follow the second element of the first batch, which was m.
See what is happening?
Thanks, @FraPochetti for such a clear explanation. I think Now I am getting the point you trying to say.
So in short if we consider the data returned from the group_chunks function to be a matrix then it would have a m rows and bs columns. For the purpose of understanding, I have created a table below, which explains the above scenario.
seqLen
Batch0
Batch1
Batch2
.
.
.
Batch(bs-1)
m
0
m
2m
.
.
.
bs-1*m
m+1
1
m+1
2*(m+1)
.
.
.
bs-1*(m+1)
m+2
2
m+2
2*(m+2)
.
.
.
bs-1*(m+2)
m+3
3
m+3
2*(m+3)
.
.
.
bs-1*(m+3)
m+4
4
m+4
2*(m+4)
.
.
.
bs-1*(m+4)
m+5
5
m+5
2*(m+5)
.
.
.
bs-1*(m+5)
The above table showcases that each batch is going to have a length of m and these each batches are going to be feed to our rnn. To understand more clearly, I looked at the LMModel2 code given in the notebook.
class LMModel2(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
def forward(self, x):
h = 0
for i in range(3):
h = h + self.i_h(x[:,i])
h = F.relu(self.h_h(h))
return self.h_o(h)
line: h = h + self.i_h(x[:,i]) will produce embeddings for the first batch i.e. Batch0 which has a seqLen of m. It will continue to generate it 3 times i.e. it will go till Batch3.
Therefore, I think Shuffling the data in this way( which is not actual shuffling but a rearrange ) just helps to represent the data in matrix form (so as to feed them in batches ).
Please correct me if I may not be clear with my understanding. Thanks
returns an object of type fastcore.foundation.L of length m * bs = 262 * 64 = 16768
whose elements are tuples of length 2
where the first element of the tuple is a tensor of shape 3 (the input OR independent variable OR the 3 tokens we use to predict the 4th)
and the second element of the tuple is an integer (the output OR the dependent variable OR what we have to predict, e.g. the 4th token)
which means that it is literally a concatenated list of 262 (m) batches of size 64 (bs), so it can be reshaped as a matrix of m rows and bs columns (as you said).
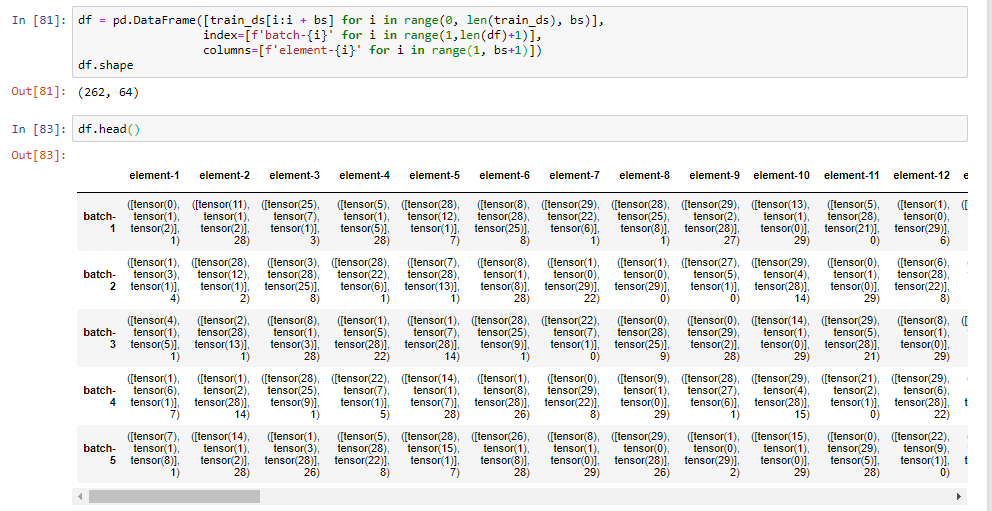
Let’s visualize this, to make sure we understand what the model sees.
I am turning the dataset into a pd.DataFrame.
As you can see, it has 262 rows (m or number of batches) and 64 columns (batch size).
Each cell of the dataframe is a x,y pair, e.g. (3 tokens, 4th token).
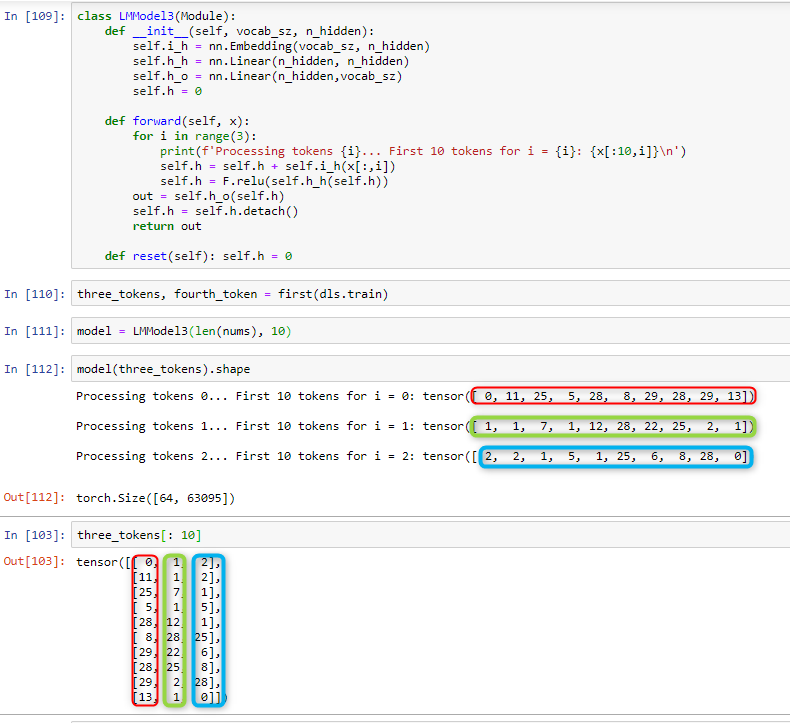
Given what we have just seen, your statement is incorrect.
A forward pass just looks at one batch at a time, looping through 3 tokens to predict the 4th.
This line h = h + self.i_h(x[:,i]) will NOT go until batch 3. The index i refers to the 3 tokens we feed the model to predict the 4th.
Look here:
 but it is not quite right yet. Bedtime time here
but it is not quite right yet. Bedtime time here  . I will formulate a clearer explanation tomorrow first thing in the morning!
. I will formulate a clearer explanation tomorrow first thing in the morning!