I know that Transfer Learning is a good practice for extending existing DL architectures for most of the applications. However, there might be cases where Transfer Learning wouldn’t work. So what is the best way to create DL architectures afresh?
Is the simple approach is to keep adding layers (Convolution, Nonlinearity, Batch Norm, etc) one after the other and keep checking the accuracy? Once you think the model is doing well, then you stop.
Or there are some special considerations to make or some advanced math knowledge or beyond layperson competencies, to devise new architectures.
If you are talking about how architectures like ResNet were made in the first place, I think after studying various papers any major deep learning news is a result of a long list of research done before it. So new things are build iteratively. And in some cases, a new idea strikes in one’s mind, these things have not worked and he invents a new thing.
In deep learning, if you are a practitioner then you will never make use of any theoretical math. Just simple math, to understand the things you are doing. The math that we do see in papers, is mostly to prove a point of their paper on why it works. And in case you are wondering, how they come up with that math, it is a result of a group where some have higher degrees in mathematics and things like optimizations are a core subject in their studies.
Simply adding layers to your model is not a good idea. As you can suffer from vanishing gradients. But in cases where you cannot use transfer learning i.e. you want some other model, then using some parts of the original model is useful and then adding some layers depending on your project is a good practice.
Building Pyhton NNs from scratch, without making use of powerful libraries such as fastai or keras, is a nice way to familiarise with data manipulation and calculus at work. A very gentle intro might come from this post http://www.wildml.com/2015/09/implementing-a-neural-network-from-scratch/ and sky is the limit if you wish to go on.
Hey @bilalUWE!
Is there a particular reason you want to have a new architecture? You could use for example a ResNet (or whatever suits) without the pre-training and train it from scratch without the use of transfer learning. I think as a practitioner that makes sense, unless you have some fancy variables in your project or want to do it for fun/learning.
EDIT: Keep in mind that you usually need a lot of data if you’re not using transfer learning!
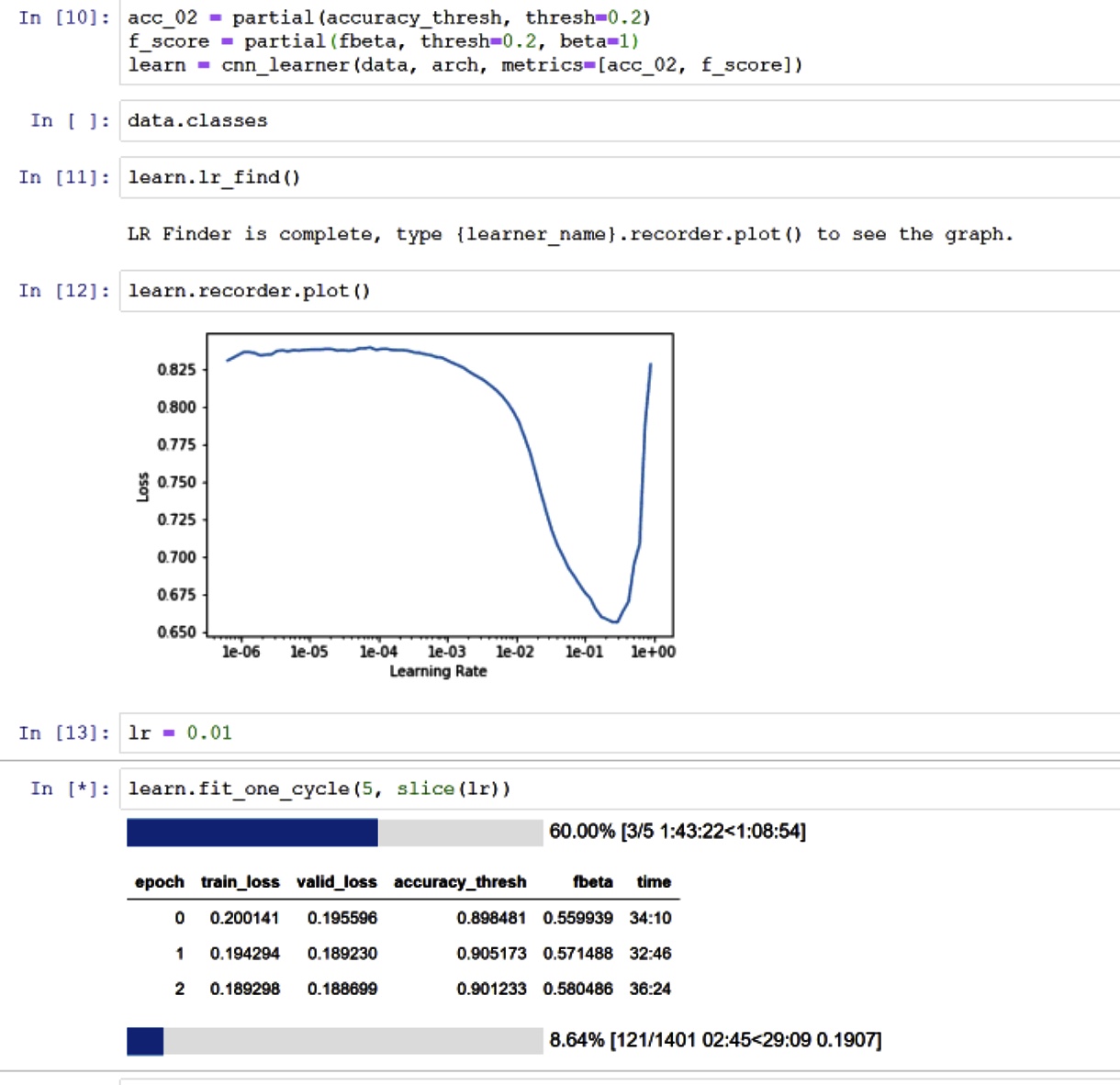
I’m working on Chest X-rays data downloaded from here. It is a multi-class classification problem to detect 14 diseases in the chest x-rays. I am using the same steps as in lesson-3 for planets. However, the results are not impressive so far. The highest F-beta (beta=2) that I have attained so far with Fast AI is 65%, provided the accuracy is up to 90%. And I tried utilising various ResNet and DenseNet architectures. I’m kind of stuck and don’t know what is wrong with my approach. One option, I was thinking was to come up with my own architecture from scratch by following the CheXNet paper. And I really don’t have much experience in creating new architectures…
There are many additional tricks that one could use. For example, if it is an imbalanced dataset, you might want to oversample or use a different loss function like Focal Loss.
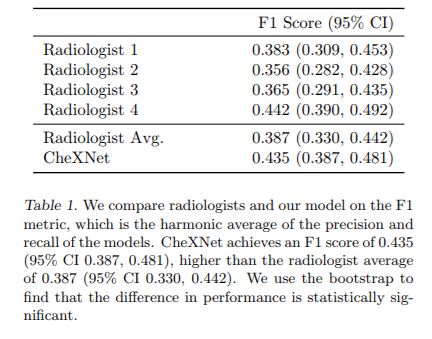
Looking at the paper, it uses F1 rather than F2, and the F1 metric is quite low (~0.4) though significantly higher than radiologist performance. So check the F1 metric and see if you have similar values.
This is exactly what I’m currently doing. I have set beta=1 for F1 score. The results are not very encouraging as F1 score is slightly lower (58%) than F2 (60%) at this stage of training. Though, I still have to train the model after unfreezing and tryout progressive rescaling. But not sure as it seems not working very well. See the results attached.
You are right. This is a great news then. I have tried several architectures of ResNet and DenseNet. ResNet is doing better than DenseNet using Fast AI library.