What am I doing wrong when training my model?
Here’s a screenshot of the LR finder in action with many worrying #na# s:
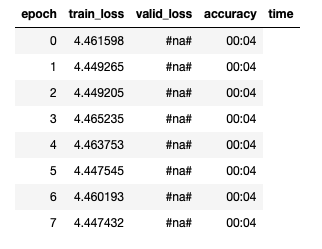
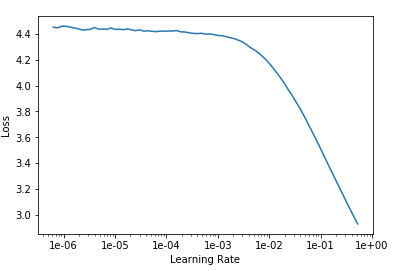
The LR graphic with a frustrating downwards slope:
And the code:
data_lm = TextLMDataBunch.from_csv(path, file, label_cols="type", text_cols="sentence")
data_lm.save('data_lm_export.pkl')
data_lm = load_data(path, 'data_lm_export.pkl', bs=bs)
model = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.01)
model.lr_find()
model.recorder.plot(skip_end=15)
The super tiny dataset I’m using is a 40-row CSV of format:
id,type,sentence
My ultimate goal is to have a model that can predict the type of a given sentence. With the above (very likely flawed model), predictions are very bad… I appreciate the data set is not huge but, because of the many #na#s in the LR finder output and the horrible slope, I suspect there is something more fundamentally wrong going on.
Any help appreciated!